Introducing Holistics Canal - a fast query streaming engine
Canal aims to provide much better performance, maintainability, and scalability throughout Holistics querying operations.

Contents
Introducing Canal
We’re excited to announce Canal, our new Connector and Caching system. Canal aims to provide much better performance, maintainability, and scalability throughout Holistics querying operations.
Realistically speaking, we think Canal achieve somewhere from 2x-3x performance improvements on average use cases. In some internal test cases, Canal has achieved over 5x performance improvements from our existing system on queries ranging from 100,000 to 500,000 rows in result sets. Check out the demo below.
Running a query that returns 500K rows, Canal vs non-Canal.
We're excited to announce that Canal is almost ready, starting with support for PostgreSQL, Redshift, and BigQuery. Other databases like Snowflake will be supported soon.
👉 If you'd like to be notified when the beta version is available, fill out this form and let us know which database you're using.
For those interested in the technical details, keep reading to learn how we built Canal.
How Canal outperforms current engine
Background
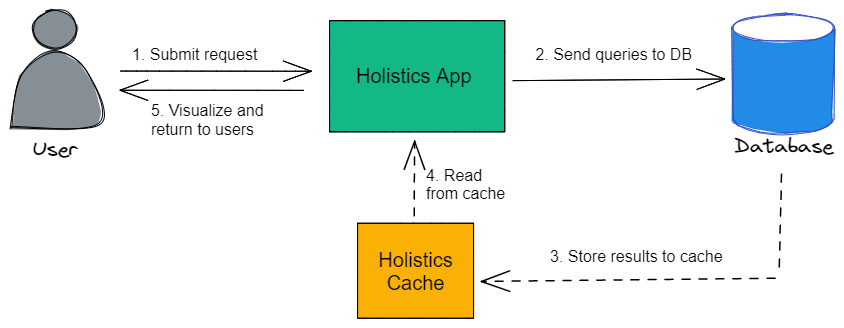
To give some context to how the existing system works, Holistics generates and sends an SQL query to the customer's data warehouse when a report is run. The query results are captured, cached, and processed before being rendered on the client side.
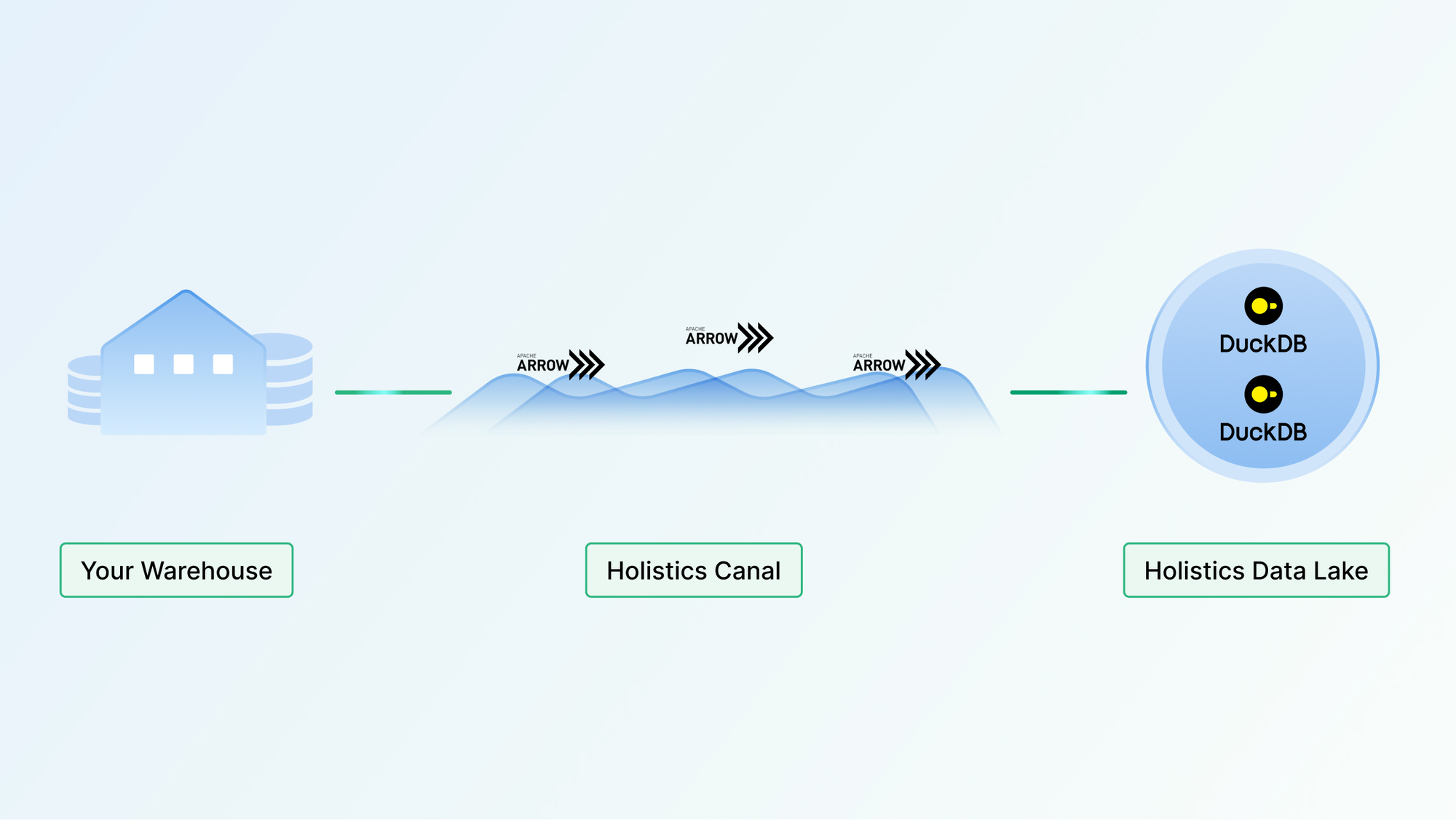
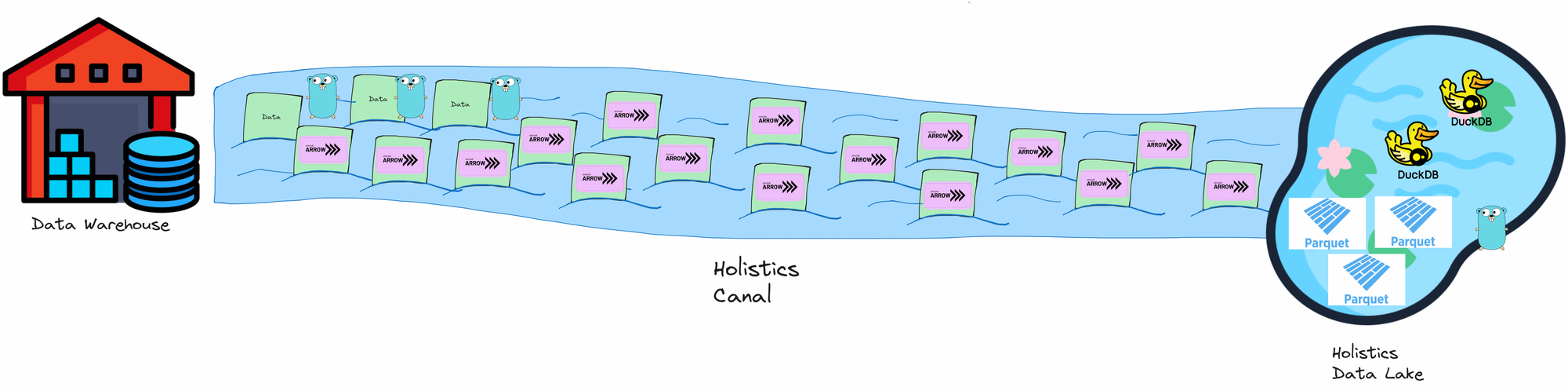
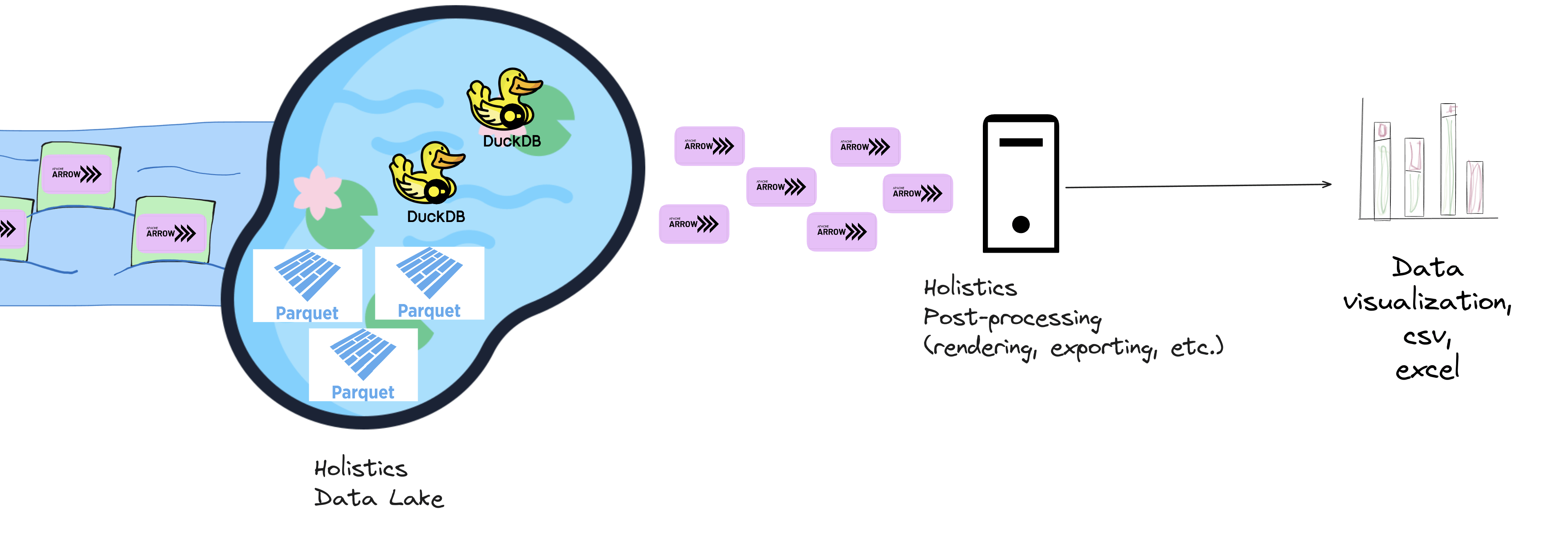
The Canal system consists of:
- Connector services: These connect, query, and stream data from customers' Data Warehouses into the Data Lake.
- Caching services (aka. Data Lake): This provides queryable, cached storage for fast data retrieval.
Canal performs better than the current system due to 2 factors: Streaming and use of better technologies.
Data Streaming
To illustrate how the Canal differs from the current engine, imagine two different logistics methods for transporting goods:
- Current engine: Like transporting goods by road using trucks.
- Canal engine: Like moving goods over water using floating packages.
Current Engine (transporting data over land roads)
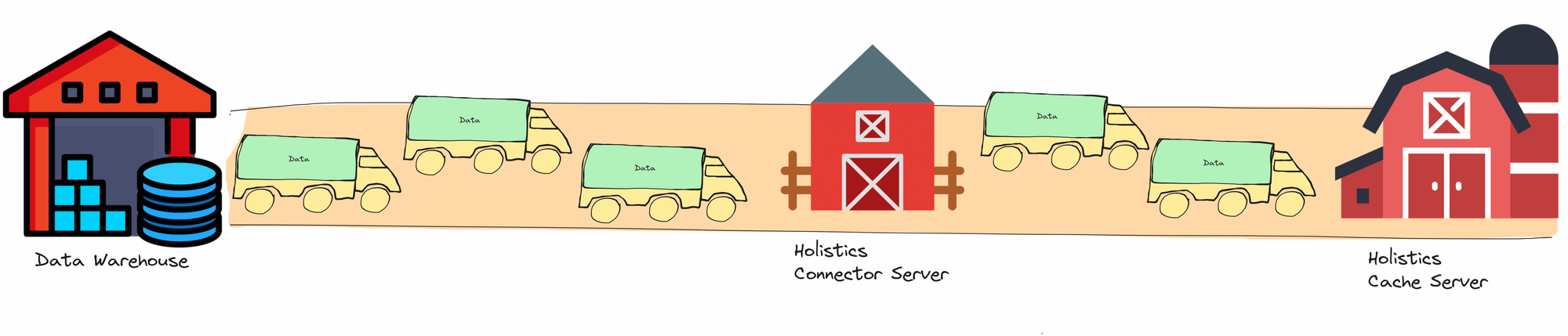
- Data is transported in bigger “trucks” (or chunks).
- The throughput is low: the road only fits a few trucks at a specific time (or road segment).
- Have to unload data into the intermediary Connector Server, then load them up onto the trucks again before transporting them to the Cache Server. This is a costly step (especially because of the concurrency issue mentioned here).
- Memory costs: the Connector Server has to carry large amounts of data in its memory.
- The memory will have to be cleaned up later (i.e. Garbage Collection) and this cleanup process also slows down the server.
- When the memory reaches the server limit, the server would slow down and might even crash.
Canal Engine (transporting data over water)
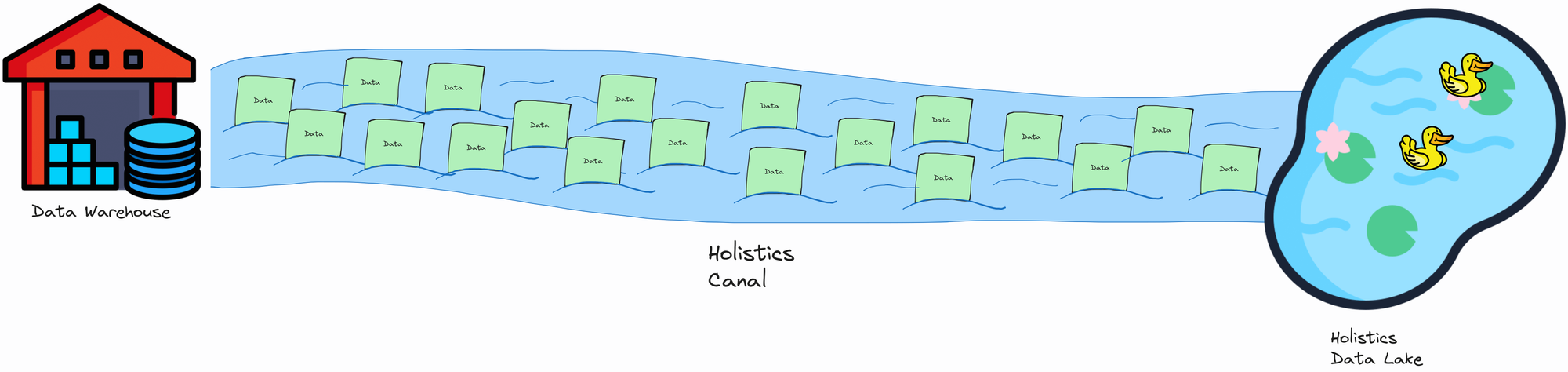
- Data “flows” as smaller “packages” or chunks through the Canal straight into the Data Lake.
- Higher throughput: the “canal” fits more packages at a time.
- No overhead of intermediary loads/unloads.
- Minimal memory costs.
Notes: The new system does not change the network speed. Hence, in the illustrations above, the speed of the “trucks” and the speed of the “canal flow” are pretty much equivalent.
Technologies
Canal utilizes newer technologies that are well-suited for high-performance data processing: Golang, Apache Arrow, Apache Parquet, and DuckDB.
Golang
The entire Canal system (including the Data Lake) is built using Golang. This offers numerous benefits, such as faster execution, better concurrency, and access to the latest data-processing libraries.
Faster execution
The previous Holistics Connector was built with Ruby, an interpreted language that relies on just-in-time (JIT) compilation during runtime. By contrast, Golang pre-compiles code before runtime, enabling faster execution right from the start.
Golang also enables us to use more efficient data structures and make lower-level optimizations in our codes.
Better concurrency
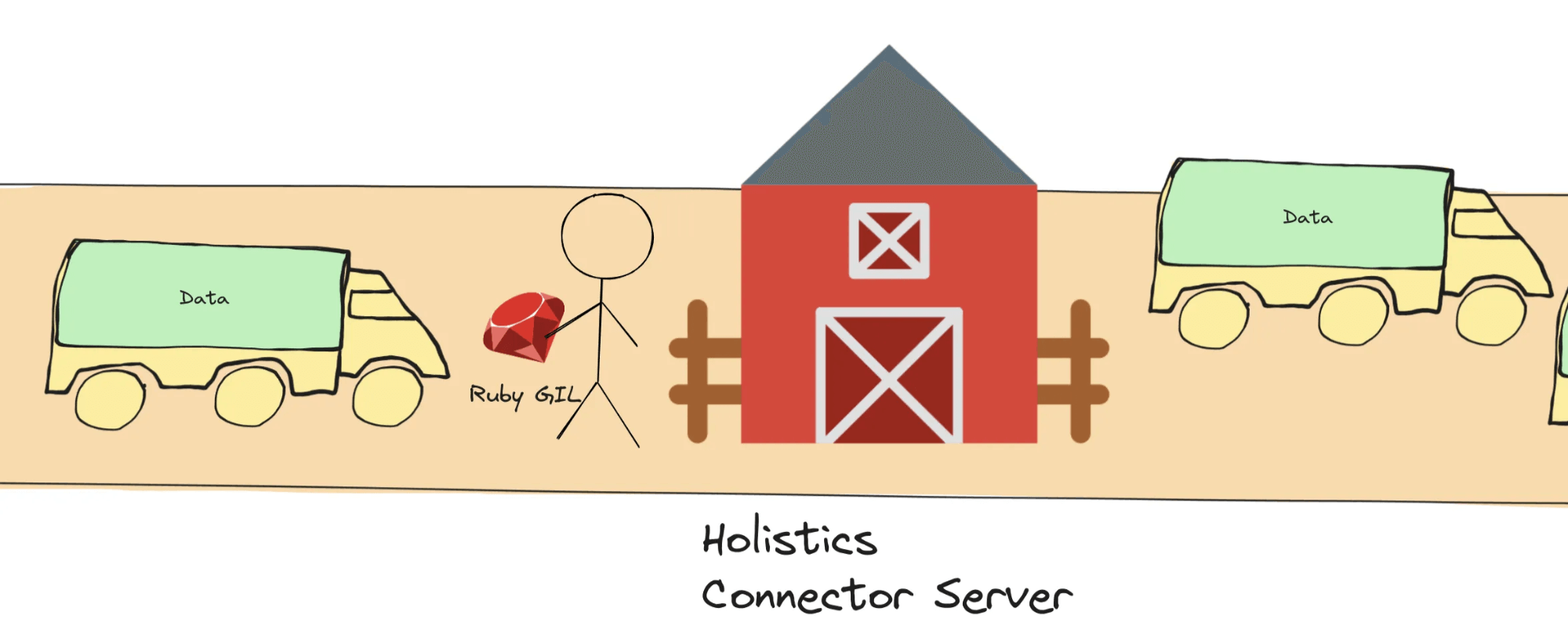
Ruby has a Global Interpreter Lock (GIL) which limits the concurrency power in certain operations.
- Imagine each connector server as a “barn”, where only one worker (the “truck”) can unload or load data at a time due to the GIL.
- The “worker” must hold the Ruby GIL to be permitted to unload data from the left “truck” into the “barn” and to load data into the right “truck”.
Hence, there can only be 1 worker unloading/loading data at a time, which slows down the whole pipeline.
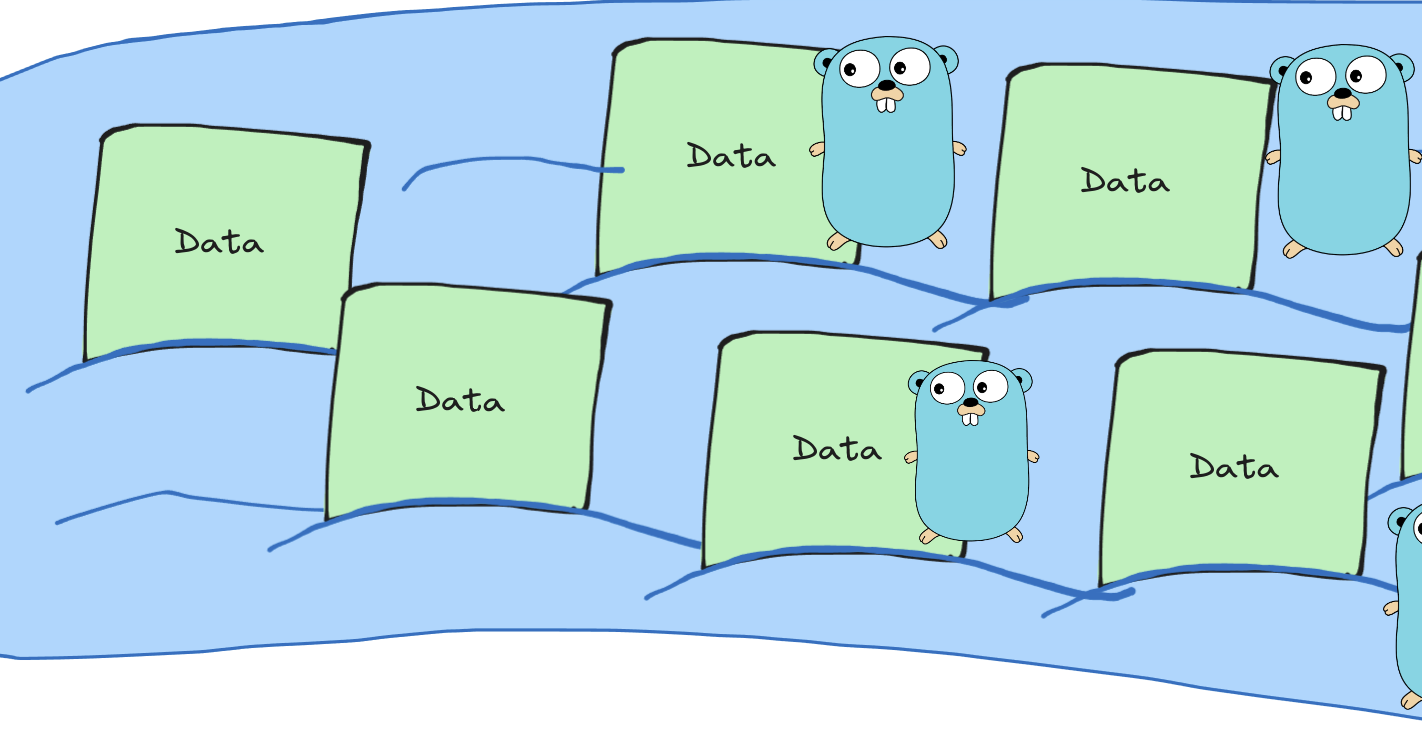
On the other hand, Golang can spawn multiple goroutines working in parallel. In our illustration, Golang allows us to operate on multiple “currents” at the same time, right in the middle of the flow/streaming.
Note: While Ruby GIL is typically a challenge to better concurrency and scalability, Ruby itself is still a great programming language with good performance and many features and libraries. Holistics still uses Ruby in a lot of its operations.
Better data processing tools and technologies
Golang has first-class support from major Databases/Data Warehouses. Thus, the Golang database connector libraries are often readily available, more performant, have more features, and have fewer bugs.
Apache Arrow and Apache Parquet libraries are also very well-maintained in Golang, while they are still pretty primitive in Ruby at this moment.
Apache Arrow & Apache Parquet
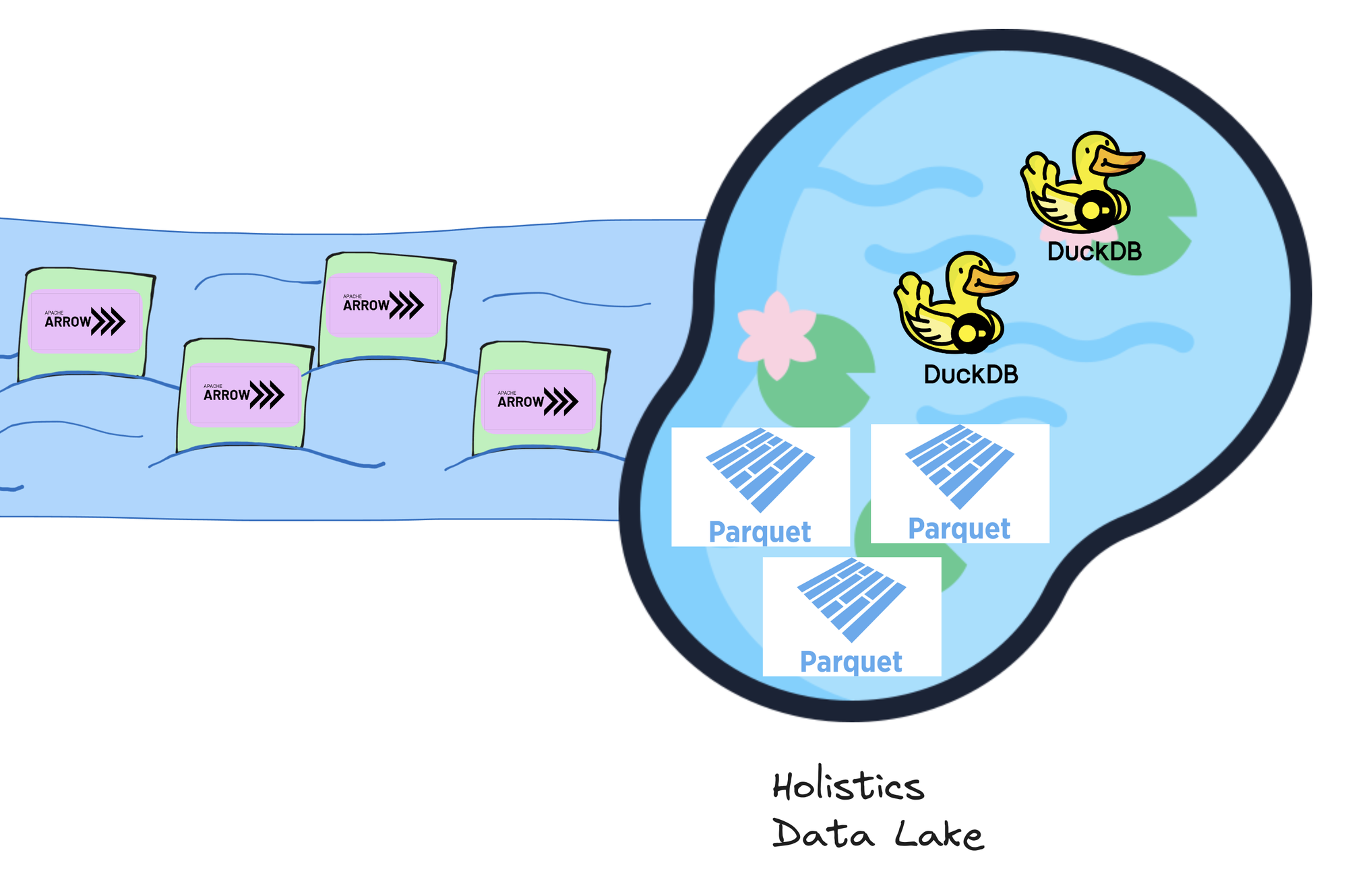
Holistics Canal uses Apache Arrow as the data format for transferring data into the Data Lake. It avoids the cost of “unloading” and “loading” data (i.e. serialization and deserialization) into and from the Data Lake.
For data warehouses (e.g. BigQuery and Snowflake) that use columnar storage themselves and provide Apache Arrow as query output format, this also avoids the cost of “unloading” data from the data warehouses.
Furthermore, it can be seamlessly stored and processed as a columnar data storage, enabling fast data analytics and retrieval.
Currently, we store the Arrow data as Apache Parquet files, which provide storage compression and portability while still being fast enough when queried by DuckDB.
DuckDB
We use DuckDB as our cache query engine because of its advanced features and speed:
- Features: DuckDB provides lots of useful querying and analytics features.
- Speed: Its vectorized query execution model allows high-performance querying on cached data. It can also output Arrow data, which again is very efficient when transferring to post-processing services.
Looking Ahead
As the tools and technologies around Apache Arrow and DuckDB are evolving every day, we can expect to incorporate more features into Holistics and improve Holistics performance even further in the future!
Comparison summary
Here’s a quick summary table that compares the current system with Canal.
| Current | Canal | |
|---|---|---|
| Data Transfer | Loads the whole result into the Connector Server before sending it to Cache Server. → Significant overheads and bottlenecks |
Streams data chunks directly from the Data Warehouse to Holistics Cache Server. → Minimal costs. |
| Technologies | ||
| Programming Languages | Ruby: concurrency performance (and hence scalability) is bottlenecked by the GIL | Golang: * Faster execution with compiled code and efficient data structures. * Better concurrency with Goroutines. * Access to better data processing tools and technologies |
| Data Format | Rowise data format. | Columnar data format: Apache Arrow and Parquet, allowing minimal serialization/deserialization and faster analytic operations. |
| Cache Query Engine | Custom-built cache system on top of PostgreSQL | DuckDB: * native support for Arrow and Parquet * vectorized query execution model |
Benchmarks
Below are the benchmarking results when querying 10 Holistics reports concurrently from a Postgresql database into the Holistics cache.
- Querying 10 reports concurrently means we query 10 reports at a time on a single server.
- Each report contains 5 columns, and we run it with different number of row limits. For each number of rows, we run the benchmark 5 times.
- This benchmark is conducted in our development environment.
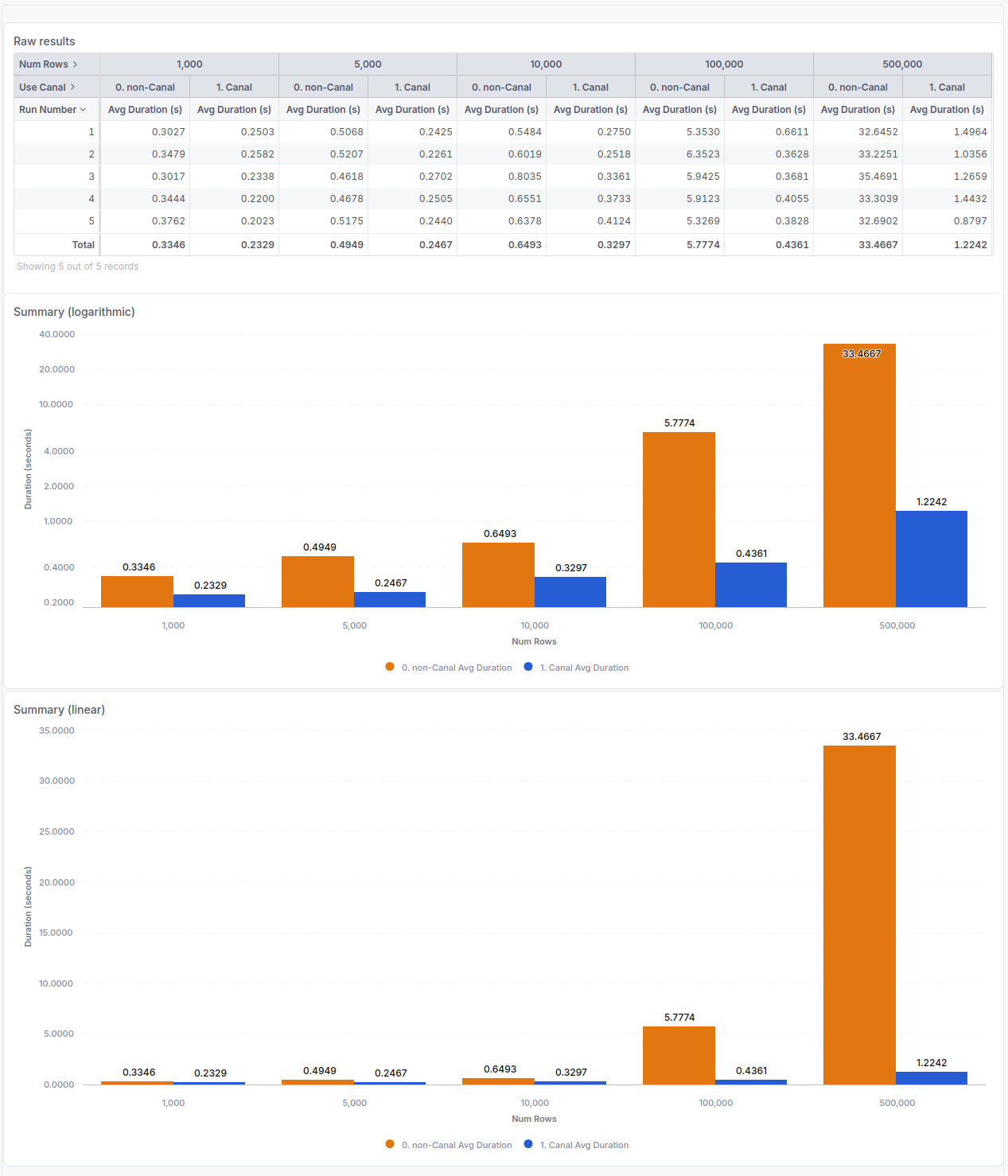
Below is a side-by-side comparison when running a report containing 500,000 rows in the result set.
Running a query that returns 500K rows, Canal vs non-Canal.
Sign up for Canal
That’s it.
As mentioned, Canal is being released as beta soon with support for PostgreSQL, Redshift, and BigQuery. Snowflake support will come after.
If you’re interested, sign up for beta here. Make sure to indicate the database you’re using.
What's happening in the BI world?
Join 30k+ people to get insights from BI practitioners around the globe. In your inbox. Every week. Learn more
No spam, ever. We respect your email privacy. Unsubscribe anytime.
