Combining Data Sources: Approaches & Considerations
Analyze how the way different vendors addresses the problem of combing data from different sources

Contents
A common feature that Data Analysts and Data Engineers often ask for in a Business Intelligence Reporting tool is the ability to combine data from different databases, especially data spread across two or more database vendors, such as PostgreSQL, MySQL, SQL Server etc. This article explores the pros and cons of different philosophies adopted by BI Vendors, and what it means to you.
Scenario
Let me start with an example: Your company is an upstart in the e-commerce space and you have implemented an order and delivery management system that stores data in SQL Server. Additionally, you collect website traffic and visit related information, and store it in a separate PostgreSQL database. Your Marketing team and the Founders want to understand the best channels that result in a purchase. Thus, your reporting solution needs to combine data from both databases, and run fast enough to provide quick drill-downs and filtering on the visualizations you intend to build.
General Solution
Some BI Reporting tools offer to provide this capability: you can use a feature, or perhaps even write one SQL that combines tables from both data sources in one query.
Let’s look at how the general design of such a solution would work, at a high level:
- Move data from one source — usually the one with fewer rows (let’s say this is PostgreSQL) — into a “temporary” location
- Execute the query and fetch results from the more voluminous dataset (SQL Server)
- Combine the two data sets in the temporary location and provide final result
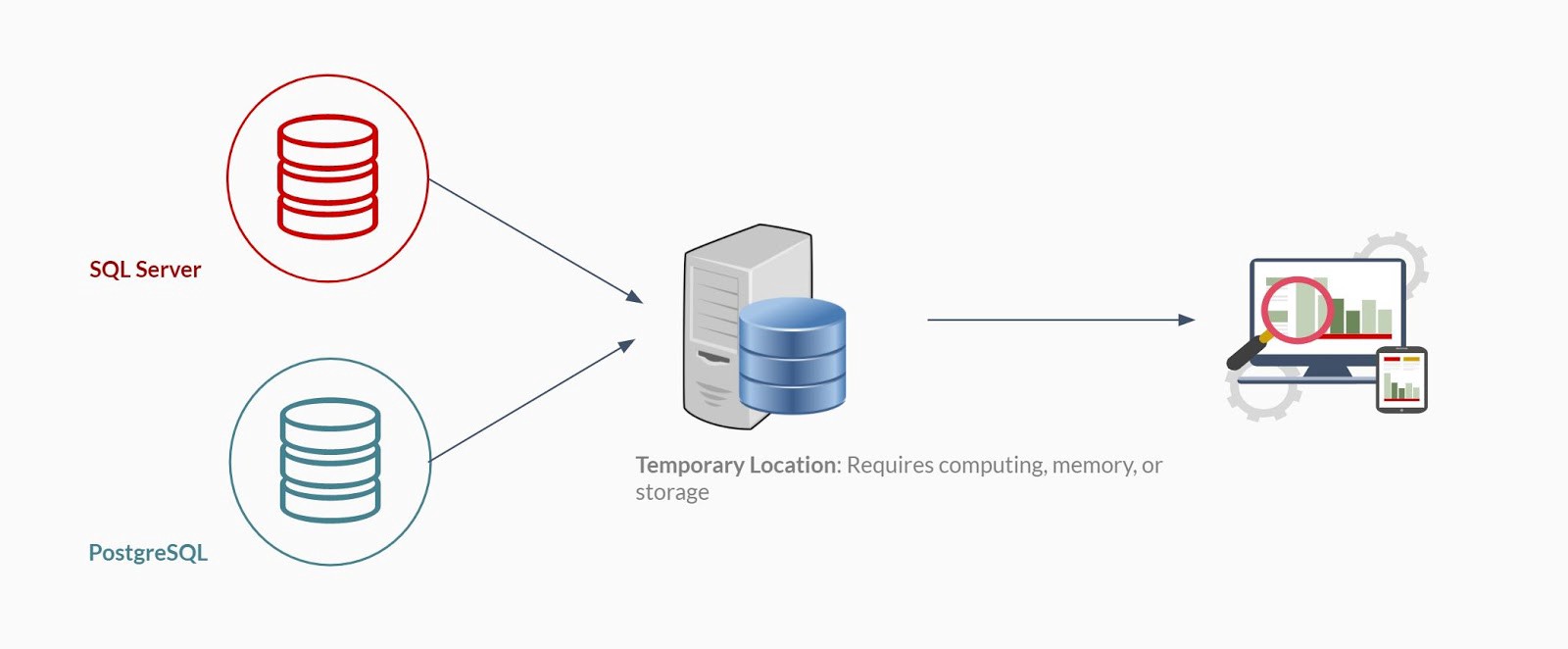
(Some BI products may have optimized one or more steps better than others, but the constraints introduced by querying and combining two data sets are the same)
The difference lies in where that “Temporary” location is, leading to 4 possible approaches:
- Data is not stored anywhere, and is stitched together in run-time
- Data is processed in-memory (No persistence)
- Data is processed in a cache database, usually provided by the BI Tool vendor (With persistence)
- Data is copied over to a common database, and all reporting goes against this common database. (Not “temporary”)
TLDR (Summary)
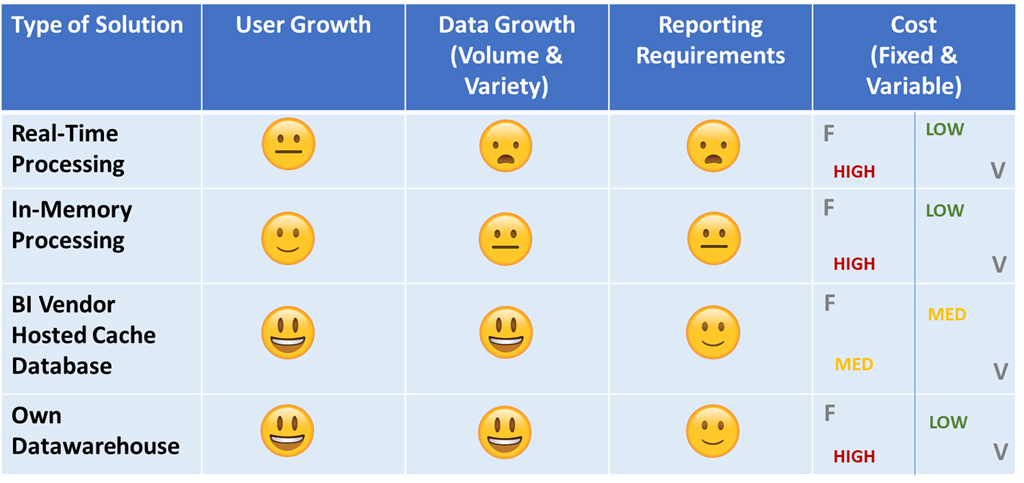
Here's a summarized version to breakdown how the 4 approaches handles the combining of data
1. Combining Data: Data is not stored anywhere, and is stitched together in run-time
The first approach is provided by BI Vendors who typically have a product that runs on a server, and essentially use the memory, bandwidth, and computing resources of the server to combine the two data sets. The best example of this is IBM Cognos BI. The disadvantage is, of course, performance.
Longer Processing Time
Combining data from two sources takes time. It involves executing queries, retrieving the results via a data transfer protocol, and stitching the data sets on the server. Delays could be introduced at any of these steps, especially if one or more of the data sources are slow to return the query results.
Difficult to scale
There are many points of failure in this approach. Thus, even if your first reporting solution performs acceptably well, it will struggle as your data grows.
Also, even a simple action like closing the report and re-opening it later will lead to re-running the entire process from scratch, resulting in a slow user experience.
2. Data is processed in-memory (No persistence)
In-memory processing can either be local (desktop/laptop) or shared (server). This can be quick once the BI tool fetches data from both sources and optimizes it for your querying and analyses.
Thus, when a dashboard or reporting solution is accessed, the BI tool takes a few seconds to minutes to combine the data set (done once per session) and then subsequent actions, such as drill-downs and filtering, perform well.
In-Memory processing runs well for small data sets
Software that runs on your laptop or desktop, such as Tableau, work really well for small data sets. When the memory used in a server, the in-memory dataset can even be leveraged by a group of people.
But struggle when the data volume grows
“Sounds great, let’s do it” — you hear yourself say. The performance starts to slow down when data grows, or the questions your users ask need more data points on the fly. I have illustrated the possibilities of in-memory processing along two important dimensions — Users & Data (Size & Complexity) below:

Thus, in-memory technology could solve the requirements today, but I would urge you to think about where your customer’s needs are headed. Chances are, your data and/or the usage patterns are going to become diverse.
3. Data is processed in a cache database (With persistence)
In this approach, the vendor cache your data at regular intervals so your database need not send a new query to your database when a user access it.
Access reports faster
Storing the data from both sources in a “cache” database ensures that your reports or dashboards run quickly. Even when reporting requirements change, the cache is repopulated behind the scenes, ensuring that your user experience does not suffer.
At the costs of stale data
The risk, however, is that the cache against which your business leaders take decisions might become stale and go out-of-sync with the operational view.
With higher data infrastructure costs
While the problem is usually solved by an auto-refresh option provided by some vendors, you will be paying for bandwidth, storage, and processing for the data hosting service in addition to paying for the reporting features.
Data security may be a concern
Now that your company’s data now resides in a cluster hosted by a third-party. In some industries, such as Financial Services, this is prohibited by regulators, and for others who intend to use BI Reporting on Customer Data, placing customer-identifying information in external servers could be of great concern.
4. Data is copied over to a common database (Not “temporary”)
This is the classic datawarehouse solution — source data into a common reporting platform, schedule the updates in batch, and ensure that there is one database for your business users, data analysts, and data scientists to leverage.
More Control
Database administrators get to enforce the security standards and may choose to establish governance policies to ensure stability and reduce the risk of crashes.
Duplicated Storage
The obvious drawback is that you create two copies of your business data and face the out-of-sync risk highlighted above.
Also, storage costs could potentially double due to the duplication. Furthermore, until a few years ago, batch update schedules often couldn’t keep up with business requirements to get data on a near real-time basis. New tools in the data streaming technology enable to overcome this problem, and provide near real-time write capabilities to your database.
Data Virtualization
Additionally, there is one class of products that span across a few of these approaches: Data Virtualization products. These software provide an abstracted view of tables across data sources, and enable a data analyst to model relationships between tables as though they were physically present in the same database. Once modeled and published, these products generate a query execution path that identifies the optimal way to combine the two data sets.
Subsequently, these models can either by cached in memory, in a database, or run on demand. Data Virtualization solutions have been increasingly adopted by large enterprises as a way to solve the technology fragmentation problem. Note that the approach you take in choosing a “temporary location” with Data Virtualization solutions will bring you back to the associated drawbacks & benefits of the approaches discussed above.
To summarize the different approaches based on what is going to change in your business: Data Volume and Variety, No. of Users, and Reporting Requirements, I’ve put together the table below:
Conclusion: What all of this means to you
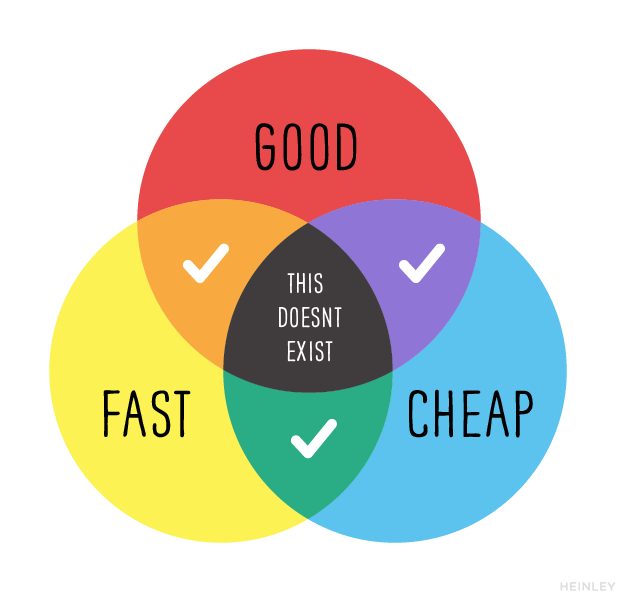
A BI Solution can be, at most, two out of the three above, making you trade-off on one parameter. The word “Good” could mean secure to some or scalable to others and many things in between. I urge you to think about where your data collection, user-growth, and existing behavior of users are headed over the next 18 months (at least) before you pick a solution to solve the problem of combining data from different databases.
This article was written by Ragha Vasudevan, an experienced BI Professional and currently a growth hacker at Holistics Software. A product-specific view of this topic has been posted here, which specifies how Holistics approaches this technical challenge.
What's happening in the BI world?
Join 30k+ people to get insights from BI practitioners around the globe. In your inbox. Every week. Learn more
No spam, ever. We respect your email privacy. Unsubscribe anytime.
