Data Teams as Product Teams, Managing Growing Teams, and Good KPI Design at Trade Republic: An Interview with Hannes Felsberg
Designing Data Organizations is brought to you by Holistics, where we delve into the intricate process of creating and optimizing data teams within organizations.


For this week’s episode of Designing Data Organizations, we spoke with Hannes Felsberg, Group Lead Data at Trade Republic, who has been with the organization since 2019.
Designing Data Organizations is brought to you by Holistics, where we delve into the intricate process of creating and optimizing data teams within organizations. In this article series, we sit down with seasoned data leaders from various industries to uncover their strategies, challenges, and success stories in designing effective data teams.
One of Europe’s most successful fintechs to date, Trade Republic is known for offering a commission-free brokerage and trading platform. Within six years’ of its founding in Berlin, it has raised more than €1 billion from leading VCs such as Sequoia Capital at a valuation of over €5 billion. It is currently operational across 17 countries and has more than 4 million customers with €35 billion of assets under management.
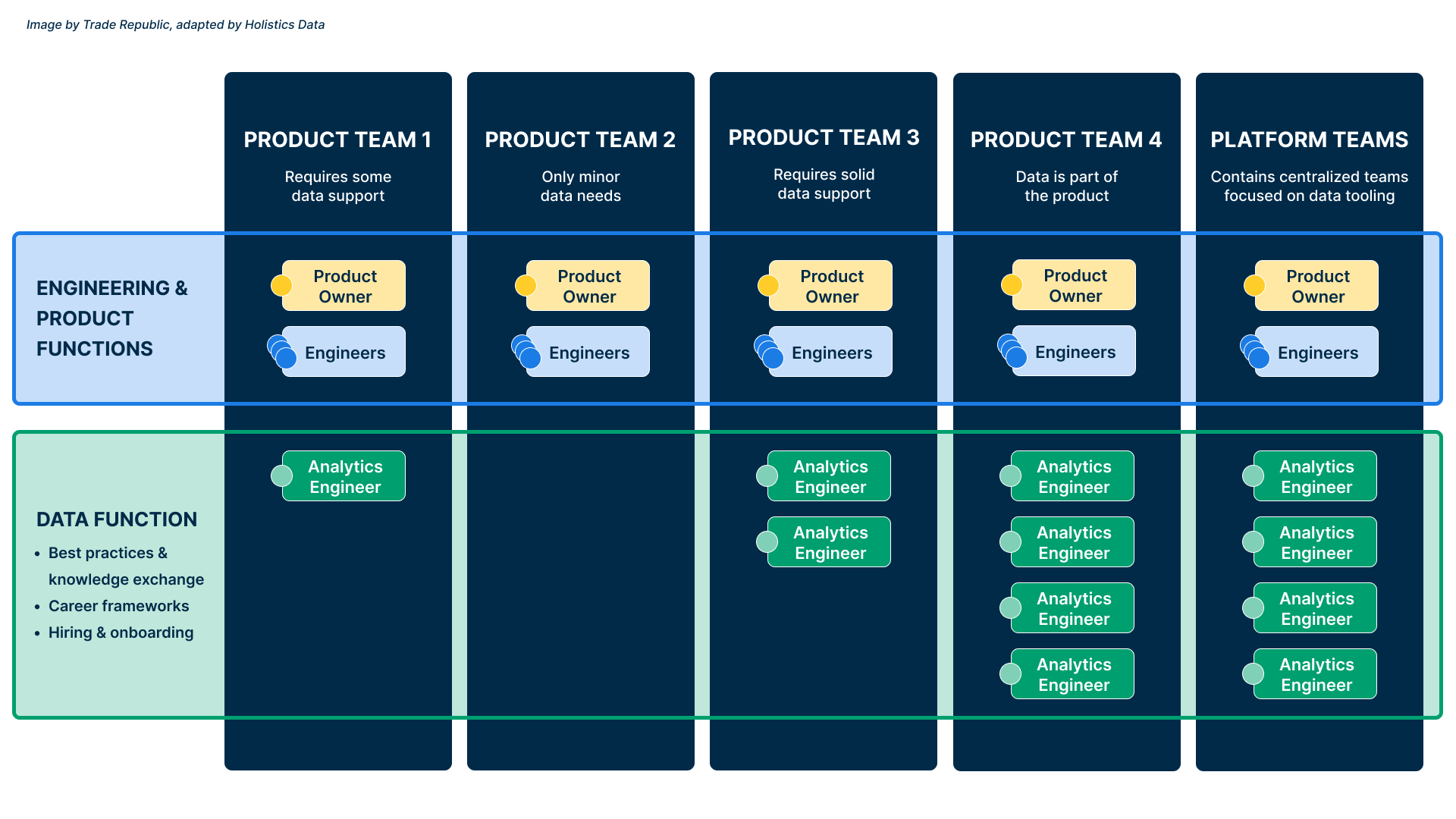
• As a product-driven company, Trade Republic treats the data organization as a product team.
• A small number of teams build the core data infrastructure, tooling, and data marts.
• Trade Republic promotes a culture whereby all product teams are capable of using and contributing to shared data assets effectively.
• Data leaders take care in striking the right balance of seniority within the data organization.
• The data org structure is not without its drawbacks, e.g. it requires significant engineering expertise for implementation.
• A good KPI = North Star Metric broken down into operable metrics with clear team ownership.
Data Teams as Product Teams
Gabriel Zhang: We’re very glad to have you in this conversation, Hannes. We heard that Trade Republic achieved its first profitable year recently despite the challenging macroeconomic conditions. Congratulations!
Hannes Felsberg: Thank you, it’s been quite a wild ride! I joined Trade Republic about 4.5 years ago to build up the data team. In that time, I have seen the company grow from 20 people to more than 600 and I’m very proud to have contributed to this success.
Can you shed some light on how the data analytics function is currently structured within Trade Republic?
It’s important to begin with the fact that Trade Republic is a product-driven organization. We have many different product teams, and there are people in each product team who take on data-related roles.
In this type of organization, there is not one data team, but data is more a functional layer, whose goal is to map out clear growth trajectories for people working with data, to create a common understanding for what skills matter, and to provide frameworks and tools that enable people to do their job efficiently.
We also have a few product teams that focus on building the data warehouse and other data platforms. These teams are made up mostly of classical data roles, such as data engineers or analytics engineers, but also include people from other functions, such as SREs or product managers.
One key thing for us, as a very fast growing company, is that we always want really ambitious people that can grow with the company and are willing to step out of their comfort zone.
It sounds like the data capacity at Trade Republic is more distributed than centralized. Tell me a little bit more about the teams that focus exclusively on data products.
There’re a couple, actually. We have a Data Platform team that’s more focused on the infrastructure; they make sure that Snowflake, Airflow, the tools that enable machine learning, tracking, etc. are all running as expected.
And then we have another team, which we call Data Foundations, who build a set of core data marts that can be used by everyone as well as some of the tooling that simplifies the data modeling process, e.g. enabling standardized testing, documentation or a data catalog.
For our business, which is at the core very transaction driven, there are many datasets where it makes sense for them to be built centrally. For example, we have the entity “customer”, which has many dimensions fed by different sources.
Likewise, transactions or trades; we’ve just launched a debit card. These entities are critical to so many teams, that they’re developed and managed centrally by the core data teams.
We also have a few additional data teams that are very product focused, for example in Anti-Financial-Crime which are, by nature, very data science focused due to the type of tasks they work on. They build products, which are essential to the company but are not producing data that’s relevant for many other teams.
My own role also has a bit of both central and distributed elements, as I’m now focused mainly on strategic analytics projects that matter across the whole company, but am also responsible for mentoring and developing our data people.
Can you help me visualize the scale of the data function at Trade Republic? Like, what’s the relative size of these teams?
It’s a bit difficult to put a number on it, honestly. The two data teams that I mentioned - Platform and Foundations - are relatively small with only five to ten people per team, but they collaborate on data topics with many other teams.
And while we do have some data analysts and analytics engineers within product teams, we also rely a lot on non-data-people who work with data in some capacity: engineers who build basic transformations in dbt, as well as product managers who might build their own pipelines, dashboards, and perform analysis.
Our approach is to enable everyone in the organization to get what they need. It’s just so much more efficient when product managers are able to write their own SQL queries, versus going to an analyst to tell them exactly what they need, then cycling back the next day for another round of iterations.
Furthermore, this approach enables them to be on top of the metrics they own, and have a deeper insight into the complex interdependencies within the data.
As a result, a lot of people spend a good chunk of their time on data topics and collaborate on topics that are relevant for data across the organization, but are not as such officially part of the data function.
Managing Growing Teams
Trade Republic has gone through tremendous growth within the last few years. How has that affected team design best practices, if any?
In terms of team design best practices, I think it really depends on what type of company you have, and your growth outlook.
One key thing for us, as a very fast growing company, is that we always want really ambitious people that can grow with the company and are willing to step out of their comfort zone.
But if you have a lot of really ambitious people, they also want to move forward with their careers quickly. So you need to make sure that you have a strategic plan for everyone, and relevant projects coming in so that you have ample opportunities lined up for everyone.
As a result, there’s always a lot of focus on where we’re heading, strategically speaking. How will the project that someone’s working on contribute to their growth? Will they eventually serve an entire product team on their own, build their own small team, and do they have technically challenging projects coming up so that they can grow their engineering skills?
Right. I imagine that it’s really tricky to have the right composition of projects and seniority within the organization for everyone to progress in their career in a fair manner.
To make all of this work, we take great care in balancing the seniority levels within our teams. It’s important to have a certain number of people who’re experienced enough to lead big and complex projects independently, and at the same time provide growth opportunities because several people want to take on more responsibilities. Meanwhile, you also need a number of people that are focused on basic but fundamental tasks.
It’s particularly difficult to maintain this in a fast growing organization. I’ve always looked into what’s happening within the next 6 months: Which product areas are hiring and how likely they will need data support, especially since hiring takes a lot of time if you want to find the perfect match. When there’s an expectation that a team’s going to grow, you have to make sure that they’re properly supported once they reach a certain size.
We really try to build analytics as internal products rather than something that just enables ad hoc analysis.
The sort of setup at Trade Republic that you’ve described - in which you have a small number of people focused on the foundational data structure, and lots of data-enabled folks in each team - makes a lot of sense for its product goals. What do you think are the strengths and weaknesses of this setup?
In our current organization, we have a lot of things going well. We really try to build analytics as internal products rather than something that just enables ad hoc analysis.
This means building tools and frameworks that allow everybody in the organization to contribute and look into data, basically the concept of “data mesh” that’s widely talked about these days. In that sense, we aren’t doing anything new. Rather, we’re just doing it in a way that’s relatively efficient for us.
Nonetheless, it has its downsides. Namely, we don’t always know how people use the data in the first place. For example, someone might run queries in a suboptimal fashion or misinterpret the content of a table. You can build the tooling that prevents this and document everything very thoroughly, but you’ll need to spend considerable effort on it.
Some things are just quicker in a classical central setup where all analytics people are very close to each other and without much effort follow the same practices.
Do you think they’re any particular aspects of this setup that will be difficult for other companies to replicate?
In an environment like ours, where we treat data as an integral part of the product teams, you’ll need a lot more analytics expertise within your engineering team. You’ll also need to somehow get visibility on what people do with the data, without necessarily being approached about it.
The type of people we hire for this setup are more senior, and much more versatile: analytics engineers who have some basic understanding of data engineering, and a sound understanding of broader software engineering practices, which can be harder to find.
For companies that just don’t have access to this sort of talent pool, it’d be really hard to execute this with the level of quality that’s needed.
Good KPI Design
Now, let’s switch topics a little bit. You mentioned earlier that you’re now more focused on strategic analytics. Would you mind sharing what you’re working on?
Sure, happy to share.
In a product-led company, when everyone is working on their own part of the product, it’s easy to lose the bigger picture. Having a set of clear and meaningful KPIs in place helps to make sure that all teams are moving in the same direction.
That’s what I am currently trying to refine for us to prepare for the next stage of growth. We need to get rid of interesting, but not actionable metrics and focus on the ones that actually matter.
For example, a very interesting metric for us as a bank is how much cash people have in their account, because you need cash to perform any other action on our platform, whether it’s investing into something or paying for dinner.
However, while customers add cash to their account to do something with it, we don’t yet know what and therefore can’t really contribute this increase to any specific team.
This means it’s not a good actionable target metric, because you cannot break it down at team level in order to give them a clear goal. We might still care about it on the company level, but need to look at it from a different perspective to find a good KPI for a specific team.
Cash in accounts is still interesting to check for sure, but you don’t want to talk about it all the time if you consider it’s harder to impact for anyone specifically.
Right. What would you say makes a good KPI?
Let’s assume that you have a North Star metric that’s clearly tied to the company’s business goals. You will need to break down how they can contribute to this North Star metric with a KPI that they have a large impact on. They don’t necessarily need to be the only team impacting this KPI, but it should be at least approximately measurable how much their actions affected it.
For example, we have a team that is in charge of our new debit card and another one that looks at our savings plans business. Both products work very differently.
But if we are looking at monthly active customers for example, it’s quite easy to say how much either of the teams contributed and we can give each of them specific goals for it that will then translate into a shared company target, which clearly matters for the company’s success. This is a good KPI.
We have found that it doesn’t make sense to have a North Star metric unless you can break it down into operable goals for teams.
Would you say that every metric at Trade Republic is owned explicitly by a team?
For our new company KPIs, yes, or at least the individual drivers that move a top level metrics substantially, like in the case just discussed. We have found that it doesn’t make sense to have a North Star metric unless you can break it down into operable goals for teams.
Once people understand how they can contribute to a North star metric, they will be able to naturally come up with the right kind of strategic initiatives themselves, enabling them to claim successes and improve on their mistakes.
I’m wondering if you’d be willing to provide one concrete example of how teams collaborate in moving the needle for a North Star metric.
Say, one team is responsible for actionable metric number one. Another team is responsible for actionable metric number two. And assuming both teams are performing, we should see changes in a common, higher-level metric.
Let’s take a look at growth: you have marketing teams responsible for bringing in new interested people, mostly measured through installs. After that, these potential customers need to go through an onboarding process with a number of legally required steps before they are actual customers.
Once they are, we need to turn them into valuable customers that actually use the product. While we are overall interested in getting as many valuable customers as possible, no team can fully own this.
But one team can be responsible for getting as many installs as possible for a certain marketing spend, the next measures what share of these installs we can convert into customers and another one what share of these onboarded customers actually ever did an action that is considered valuable.
Together they produce a metric that’s very relevant for the business, and each team can clearly measure their impact on it.
The teams themselves can then internally measure a lot of other metrics around it that might help explain changes in their KPI, such as opening rates of reminder emails within the onboarding flow, or the duration of particular steps in that process. Both of those would in turn influence the conversion rate of install to onboarding again.
Yes, that makes a lot of sense. That was a lot of information and we’re super grateful that you shared all these insights. I’m sure that many of our readers will feel the same.
You’re welcome, and thank you for organizing this.
What's happening in the BI world?
Join 30k+ people to get insights from BI practitioners around the globe. In your inbox. Every week. Learn more
No spam, ever. We respect your email privacy. Unsubscribe anytime.
