How We Built A Job Queue System with PostgreSQL & Ruby For Our B2B SaaS Application
Why and how we built a multi-tenant job queue system for our B2B SaaS Application with PostgreSQL and Ruby

In web application, a background job queue system is important for applications that need to process long-running operations (e.g, resize image, scan resume files, analytics workload). Solutions like RabbitMQ (message queue), Celery, ActiveMQ, Sidekiq, etc are well-designed and pretty popular among the industry.
In this post, I'm going to share how we designed and built a multi-tenant job queue using Ruby/Rails + Postgres for our B2B SaaS Application. I'll explain the high-level problem, why and how we did it, and also go into some specific code details to make the explanation better.
Our Background & Requirements
Our application (Holistics.io) is a SQL-based BI Platform that helps data teams build automated reports and dashboards and deliver to the end users. We've worked with customers ranging from small startups to tech unicorns and IPO companies.
Our backend stack:
- Ruby and Rails, running on PostgreSQL database
- haproxy, nginx and Unicorn
- Sidekiq (and Redis) for background job engine
How It Works: In the platform, whenever someone submits a request, we construct a SQL query that sends to our customers' database, wait for the results, and visualize the charts based on it.

Since the analytics SQL query takes time (a few seconds to minutes), it's not a good idea to use synchronous web requests, thus a background job queue system is needed to handle this.
For us, we have the following requirements to our job queue:
-
Persisting Jobs' Information: For each of the background job, we need to track the basic statistics of the job: status, run duration, start time, end time, how many records returned, etc.
-
Multi-tenancy: Each customer should have their own job queue that shouldn't affect each other, and each job queue can have different queue size (i.e customer A have 5 slots that can run 5 concurrent jobs, customer B has 3 slots that can run 3 concurrent slots)
-
Reliability: The job queue needs to perform reliably as our customers' analytics needs depends on it. Jobs should be picked up in the order they send to the queue, it should also have a retry mechanism to prevent sporadic error like network issues.
Building a Multi-tenant Job Queue in Postgres
After a few development iterations, we now have a working job queue system built with Rails/Ruby and Postgres, managing and picking up jobs from the queue to be processed. Once the job is picked up, we then pass them down to Sidekiq for the actual background execution.
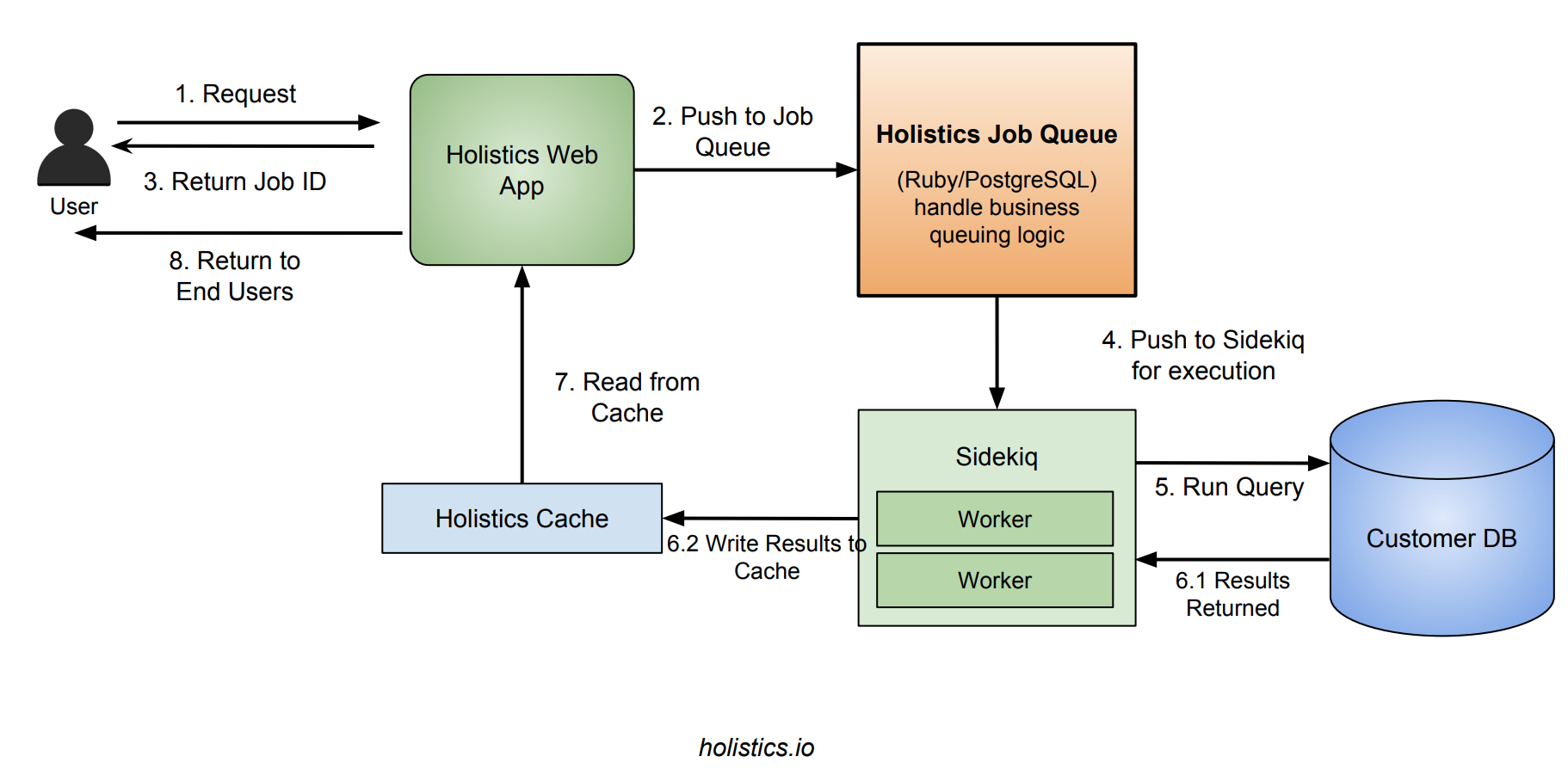
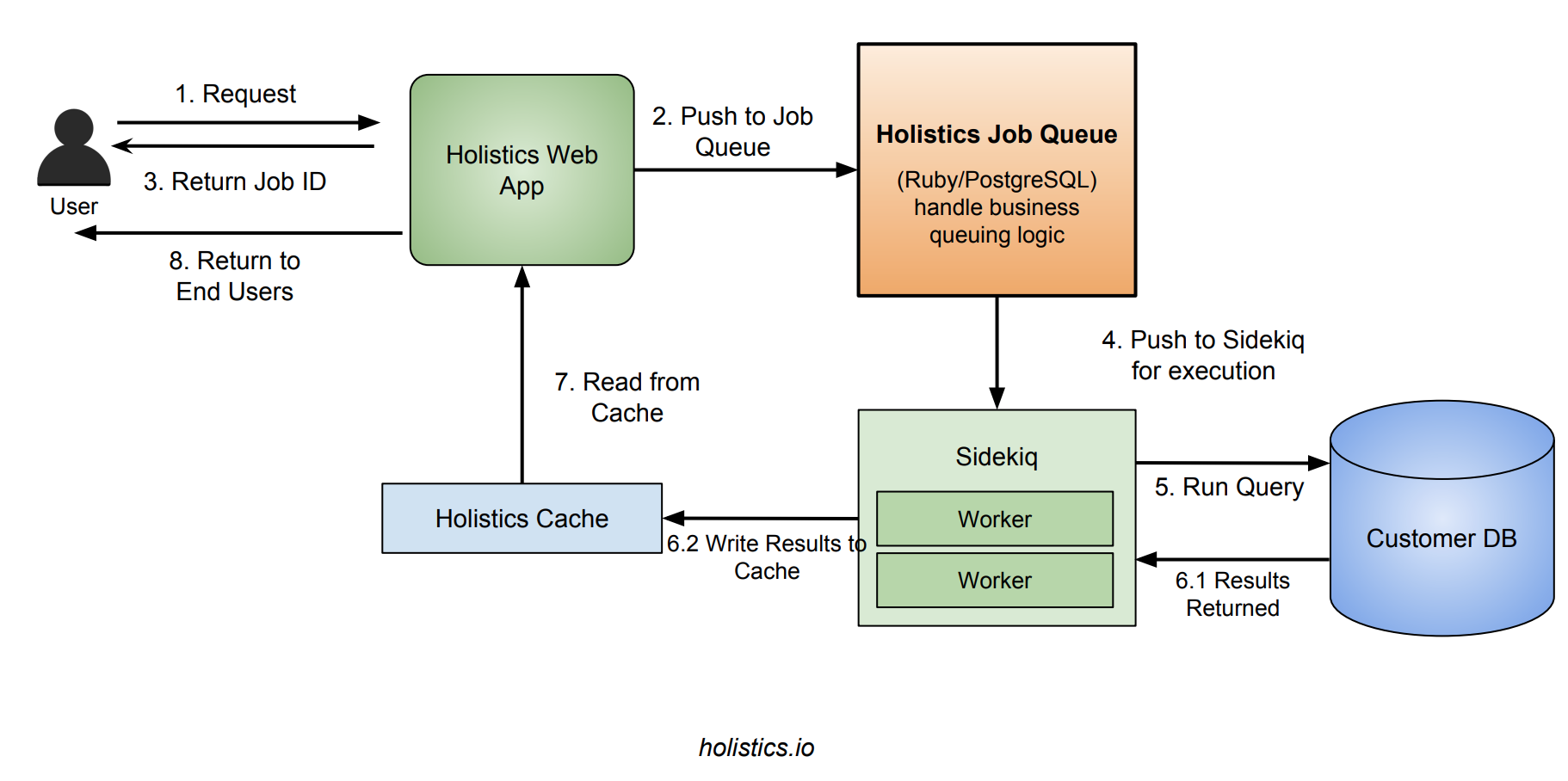
Our request workflow would look like:
- User submits request to web server, web server creates new job and pushes to our jobs queue engine. Web server returns a job ID to client.
- The job engine pick next job to be processed, and push down to Sidekiq
- Sidekiq picks up the job and execute it, writes results to cache and update Job status in
jobstable. - Client keeps polling web server for the job's status until either
successorerror. Once success, web server fetch results from cache and return to client.
Why Another Job Queue? And Why PostgreSQL?
You may be wondering why we "reinvented the wheel" and took effort to implement another job queue sytem, on top of PostgreSQL. Here are the main reasons we did it (and with PostgreSQL - our production DB)
-
Persistence: Unlike other fire-and-forget job queue system, we actually do need to store each and every job, together with their stats/statuses and expose them to the customers later on. DIY this in PostgreSQL will make this convenient.
-
Custom Queuing Logic: our scheduling logic has a number of custom logics that makes using other existing job queue complicated. Logic like multi-tenancy above, or limit number of concurrent jobs per each user account of the tenant.
Using other existing job queue system will make achiving the above 2 objectives more complicated.
On the flip side, we recognize the following disadvantages:
-
Scalability: there is no horizontal scaling as number of concurrent requests increase, but for a B2B application the growth shouldn't be as crazy as B2C.
-
Performance: Job queuing logic can get slow when our
jobstable get huge (which for our case it did), but with proper indexing and DB maintenance/tuning, this can be managed. We also performed table partitioning to keep the active dataset small in size.
Storing & Submitting Jobs
When user submits a request, we need some mechanism to store each job's metadata. We create a jobs table for this purpose.
CREATE TABLE jobs (
id INTEGER PRIMARY KEY,
source_id INTEGER,
source_type VARCHAR,
source_method VARCHAR,
args JSONB DEFAULT '{}',
status VARCHAR,
start_time TIMESTAMP,
end_time TIMESTAMP,
created_at TIMESTAMP,
stats JSONB DEFAULT '{}'
)
In our design, a job's status can take the following values:
created: when it's first createdqueued: this is when it's been picked up and pushed to Sidekiqrunning: when sidekiq worker picks up the job and starts executing itsuccess: the job succeedederror: the job failed
What's interesting is, because of our dual queue layer nature (our own logical job queue, and Sidekiq, which is essentially also a job queue), we have both created and queued status for a job.
The start_time - queue_time should be minimal and close to zero, but if this number increases (job is being pushed to Sidekiq, but there's not enough Sidekiq workers to handle them) then we know we need to add more Sidekiq workers.
Handling The Job Queue Logic With PostgreSQL
A job queue system would need to support the following:
- Ability to pick the next available job that no one has claimed, and claim it
- No two processes would be able to claim the same job, and each job should eventually be processed (exactly-once); this proves harder than it looks
- If somehow the processing of that job fails due to unexpected event (network failure, worker node failure), not failed by job logic, the job needs to be released back into the queue.
It turns out, building a job queue using PostgreSQL/SQL that supports the above constraints in more difficult than it looks. Mostly, we couldn't figure out a way mark the job as taken, but release it back when somehow the worker processing the job fails (timeout, OOM, network failure, etc), thus the job is then lost.
We tried different variations, until we chanced across SKIP LOCKED feature of Postgres 9.5, which is designed specifically for this purpose. Read this link by Craig Ringer to learn more.
The idea is this:
- In a transaction, you write a SQL query to get the next available row that's not been locked, then you do row-level locking on it, so as long as the transaction is still on (you still claim it), no other process can claim it.
- If your job succeed, you update the row status to
successand ends the transaction - If your process crashes, the transaction is automatically aborted, unclaiming the row.
Please read on the actual code below.
Supporting Multi-tenancy
Additionally, we have different customers that require different queue. We represent this with a tenant queue table like so, where (tenant_id) is unique.
CREATE TABLE tenant_queues (
id INTEGER PRIMARY KEY,
tenant_id INTEGER,
num_slots INTEGER
)
Job Deduplication Mechanism & Retry Mechanism
A lot of the time our users accidentially abuse our system by accidentially presses refresh in the report page, causing a new query job to be generated and sent to background, overloading the system unnecessarily.
For this, we've also baked in a job deduplication mechanism. Every time a job is submitted, it checks for idential job (job that generates the same query to DB) that has just been submitted but not finished in the past 10 minutes. If found, it simply returns the old job ID.
We've also added a retry mechanism, automatically rerunning the job in case the process crashes (OOM or other unexpected event) up to a configurable number.
Walking Through The Code
Consider the following SQL that basically: find the next first available job (by creation order) whose tenant still have available slot, that's nobody has claimed (SKIP LOCKED), and claimed it for myself (FOR UPDATE)
-- finds out how many jobs are running per queue, so that we know if it's full
WITH running_jobs_per_queue AS (
SELECT
tenant_id,
count(1) AS running_jobs from jobs
WHERE (status = 'running' OR status = 'queued') -- running or queued
AND created_at > NOW() - INTERVAL '6 HOURS' -- ignore jobs running past 6 hours ago
group by 1
),
-- find out queues that are full
full_queues AS (
select
R.tenant_id
from running_jobs_per_queue R
left join tenant_queues Q ON R.tenant_id = Q.tenant_id
where R.running_jobs >= Q.num_slots
)
select id
from jobs
where status = 'created'
and tenant_id NOT IN ( select tenant_id from full_queues )
order by id asc
for update skip locked
limit 1
We define a queue_next_job() method to pick up the next job, and pass them down to Sidekiq for execution. Pay attention that it's wrapped in a transaction, so that while updating the status to queued, no other process can claim the job, making sure it's never picked up twice.
class Job
def queue_next_job()
ActiveRecord::Base.transaction do
ret = ActiveRecord::Base.connection.execute queue_sql
return nil if ret.values.size == 0
job_id = ret.values[0][0].to_i
job = Job.find(job_id)
# send to background worker
job.status = 'queued' && job.save
JobWorker.perform_async(job_id)
end
end
end
And in our JobWorker (run by Sidekiq), we simply set the status to running, and actually perform the work.
# simplified code
class JobWorker
include Sidekiq::Worker
def perform(job_id)
job = Job.find(job_id)
job.status = 'running' && job.save
obj = job.source_type.constantize.find(job.source_id)
obj.call(job.source_method, job.args)
job.status = 'success' && job.save
rescue
job.status = 'error' && job.save
ensure
Job.queue_next_job()
end
end
Notice the queue_next_job() call in the ensure block. Unlike other job queue system, where there's usually a supervisor process that keeps monitoring the queue, picks up the job and hand them over to the next available worker. For us, we do away with the supervisor/worker concept, and simply utilize the current worker to invoke queue_next_job right after it finishes processing current job (scheduling work) and let Sidekiq handle the background worker running for us.
| Other Job Queue | Our Job Queue | |
|---|---|---|
| Master | Dedicated process to receive request | SQL + inline with existing Rails or Sidekiq process |
| Workers | Dedicated processes or threads | Pass over to Sidekiq |
A Note on Sidekiq: Sidekiq is a great background job worker system. We've been using it and will continue to do so (in fact we're a paid customer). Our Postgres job queue runs on top of Sidekiq, handling the finer business logic of the jobs, whereas Sidekiq will take care of the actual job execution.
Also, due to the nature of our jobs (extra-long running time with potentially hogging memories causing OOM), we made some suggestion to Sidekiq, added a process-level monitor, and a memory threshold management mechanism on top of these Sidekiq processes, which I hope to share in another blog post.
Abstracting the Background Job Logic
As part of our job queue system, we introduce an .async method chain in Ruby (thanks to Ruby's metaprogramming, making switching between synchronous and asynchrous extremely simple.
In the below code, the DataReport#execute method can be written once and run both synchronously and asynchronously.
report = DataReport.find(report_id)
# normal: execute synchronously, this returns the return value of `execute` method
report_results = report.execute
# execute asynchronously, this returns a job ID (int)
job_id = report.async.execute
By doing this, we've also totally hide Sidekiq away from the object that uses it. A new adapter can be easily written to support another background worker system. Observe that this is similar to the Promise concept in JavaScript.
Also, do note the (source_type, source_id, source_method) combination in the jobs table above, this is basically polymorphism, and how we split the job into different job types seamlessly.
Conclusion
In this post, I laid out how and why we designed our multi-tenant job queue system using Ruby, PostgreSQL and Sidekiq. We now have a flexible, reliable job queue system that works well for us:
- Jobs submitted are now persisted in a jobs table, making it easy for us to do analytics or expose to our customers
- Multi-tenant queuing logic is handled, allowing each customer to have their own queue without interfering with each other, yet allow us to utilize shared CPU resources better.
- A nice code abstraction that's easy for our developers to work with.
Along the process, we learned a ton about job queue, PostgreSQL locking mechanism, and ruby metaprogramming :)!
If you have any feedback or comments, feel free to drop in the comments section below.
What's happening in the BI world?
Join 30k+ people to get insights from BI practitioners around the globe. In your inbox. Every week. Learn more
No spam, ever. We respect your email privacy. Unsubscribe anytime.
