LLM Is Not Enough (For Self-Service Analytics)

Contents
Introduction
A few weeks ago, Microsoft announced a new data analytics product called Fabric. One of Fabric’s most exciting features is a chat interface that allows users to ask data questions in human language. So instead of waiting in a data request queue, everyone gets instant answers to their data questions.
Since the release of OpenAI and open-source LLMs, analytics vendors from big to small are scrambling to integrate modern LLMs into their products. Between Microsoft and a flurry of data vendors with shiny demos and glitzy promises, the future seems bright. “Unlock hidden insights with AI,” they say, “The power of AI at your fingertips” they proclaim. And so it goes, on and on and on.
Beneath the surface, the truth is often far less glamorous.
An AI assistant can give you instant answers to your data questions, but can you trust them?
There is a big difference between being fast and being reliable. I can give you the answer for 4566 * 145966 in 1 second. It’s fast, but it’s certainly not correct, just like how the SQL query generated by the AI assistant in the Fabric demo was not correct (despite being generated quickly).
Guys, maybe check the SQL query before doing the demo video?#MicrosoftBuild #MicrosoftFabric pic.twitter.com/OuLUk8YLep
— JP Monteiro (@JPedro_Monteiro) May 23, 2023
This is not a rare case. In this article, an analyst tries to use ChatGPT to generate SQL in a showdown between humans and machines. ChatGPT was right about 50% of the time. This is fine when used by analysts who can check the validity of the output, but a total disaster as a self-service analytics tool for non-technical business users.
This is not to say that LLMs have no place in the BI world. We’ve all seen the power of LLMs in the palms of data analysts: quickly generating SQL/Python code for ad-hoc analysis, brainstorming ideas during research, or eloquently summarizing complex analyses.
But before you’re convinced that LLMs can be easily integrated into your current BI tool to make your self-service dream come true*,* let’s take the whole thing with a healthy dose of skepticism. Let's seek proof, not from glossy brochures and snazzy demos, but from first-principled reasoning and understanding the very components that LLMs are made of.
This series is divided into 2 parts.
In part one (this post), we’ll try to convince you that: Yes, LLM will change the landscape of self-service analytics, but it will not be done quickly, nor the technology by itself is enough to power next-generation self-service BI tools. We’ll also show why data semantic layer is a crucial component in building an LLM-powered self-service analytics system.
In part 2 (subsequent post), we’ll show why we think the current design of data semantic layer is not enough for such a task, and what are the missing ingredients for that to happen.
Now let’s start.
A Conversation with AI
Imagine a perfect world where business users and analysts live in peace, free from report-sprawling, dashboard flooding, and request queue frustration - where LLM becomes an integral cog in any Business Intelligence machine. Forget about all of the how-to technicalities. Forget about all of LLM’s current limitations. Imagine a conversation between a business and AI. What would it be like?
In this article, the author painted a vivid picture of how the talk would go:
"👶 User: How can I double our company’s revenue?
🤖 AI: To double revenue, consider focusing on the following areas: Conversion Rate, Activation Rate, Retention Rate, Expanding product offerings, Entering new markets, and or changing pricing strategy.
👶 User: Extract the Conversion Rate
🤖 AI: I’m sorry, could you please provide more context? Which conversion rate data are you referring to? Currently, we have already predefined these metrics: Web to Signup Conversion, Signup to Paid Conversion.
👶 User: Show me Web to Signup Conversion Rate
🤖 AI: Our average Web to Signup Conversion Rate last 3 months is currently 5%. By increasing the conversion rate to 12%, you have the potential to double your revenue
👶 User: Provide me with a breakdown of our conversion rate over the past 12 months, organized by city.
🤖 AI: Here is the breakdown of our conversion rate over the past 12 months, organized by city. San Francisco started at 5.0% and reached a peak of 5.8% in December. New York started at 4.8%, peaked at 5.6% in September, and fluctuated between 5.2% and 5.6% until December. Seattle started at 4.2%, peaked at 6.2% in November, and decreased to 5.4% in December. Overall, Seattle had the highest conversion rate with a peak of 6.2% in November. San Francisco showed a gradual increase, while New York had varied trends. This data can help us identify areas where we may need to focus our marketing and sales efforts to improve conversion rates in specific cities
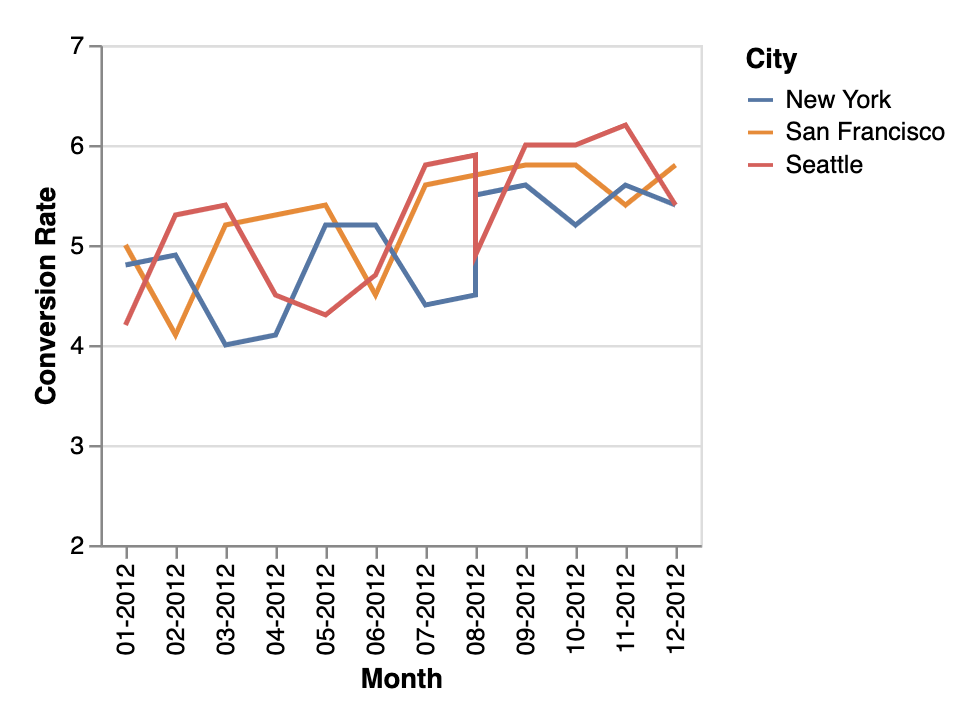
👶 User: Add this chart to my dashboard “My KPI” and set up a daily alert to be sent to me via Slack
🤖 AI: Sure, I have added the chart to your dashboard “My KPI” and set up a daily alert to be sent to you via Slack. You will receive a notification every day with the latest conversion rate data for San Francisco, New York, and Seattle."
If we carefully examine the above, we can see that the AI Assistant has the following capabilities:
- It knows about the "available metrics" and the causal relationship between company revenue and these metrics
- It knows how to generate a database query given the user input, and how to run the metrics query to get the output data.
- It can unravel the visual output in natural language and it can save the chart output to the BI tools' library of dashboards.
All these capabilities seem like something LLMs can do if you just look at the plethora of BI vendors’ demos. We will go through these and show you how hard it is to get them to work properly.
The Key Requirements
To get a sense of how difficult to get this system to work, let’s go through the requirements for an LLM to be integrated into a self-service analytics system.
Capability
First, in terms of capability, the system needs to understand the requests from users, map the requests to pre-defined metrics and queries, or even create new metrics.
It also needs to be able to formulate appropriate queries, send them to customers’ data warehouse to execute, then visualize the output.
Furthermore, the system should be able to analyze and interpret the output to recommend end-users with proper courses of action.
None of these are inherent capabilities of LLMs, so adapting the LLMs to the analytics domain becomes imperative. And it’s neither quick nor easy as we wish it could be - but more on that later.
Reliability
Secondly, in any self-service business intelligence (SSBI) system, reliability is of the utmost importance. Without reliability, the system risks presenting wrong data and incorrect interpretation - all of which graw at users’ trust in the system, and consequently the system loses its reason to exist.
To sidestep this pitfall, the system needs to uphold the integrity of the entire process, from understanding user inputs to processing and generating the final output. If there is any ambiguity in the requests, it needs to be able to detect and ask clarifying questions to the users. This is incredibly hard to get right, as illustrated by this article.
Accuracy
Thirdly, as LLM is quite prone to hallucinate its output, the system also needs to ensure the query generated as well as the analysis and interpretation are not something made up but closely aligned to the business’s available data and situation. This is virtually impossible to fix without human interference. You need both business expertise and the critical thinking skill of a human data analyst.
Then again, involving an analyst might defeat the purpose of a self-service interface in the first place.
Security & Governance
Furthermore, security and governance are also key requirements when it comes to self-service analytics. Any SSBI system needs to ensure that users can not access data they don’t have permission to. Given that LLM is prone to attacks such as prompt injection and no easy technical solution for the problem, integrating LLM into an SSBI system while guaranteeing security remains a Herculean task.
Data leakage risk continues to exist when commercially available LLMs continue to send data to third-party AI services such as OpenAI or Anthropic. And the risks here are not theoretical at all, Samsung already banned the use of ChatGPT internally due to the leakage of internal data. Compliance requirements such as SOC2 will balloon up to be a much bigger challenge.
Cost & Speed
Lastly, cost and speed affect the viability of deploying and utilizing the SSBI system. Advanced LLMs models like GPT-4 demand a deep pocket, whereas cheaper models might not meet the requirements for capability and reliability mentioned above.
In terms of speed, ChatGPT and similar tools create this expectation of instant answers. However, as an AI analyst assistant would need to run through various complex steps - including retrieval, planning, and execution, the expected results can take a significant amount of time to be produced. Balancing the trade-offs between capability, reliability, and speed is not an easy task.
Adapting Large Language Models To New Domains
In the previous section, we listed the key capabilities that are required for the SSBI to provide a natural language interface to the users. These capabilities are not an inherent part of most LLMs available on the market nowadays. Those are general-purpose models, built to be a solid base and to be adapted to specific domains afterward.
So how exactly can an LLM be adopted to a new domain?
Any specific domain has two components: the knowledge aspect (The “what” of the domain) and the skills aspect (the “how” of the domain).
For example, let’s say we want the LLM to be adapted to be a business analyst assistant. In such a scenario, here's the breakdown of our two primary components:
- The what: Key concepts, processes, and events associated with eCommerce such as orders, inventory, shopping carts, shipping, and fulfillment. Parallel with the “What” of eCommerce is the “What” of the data analytics domain which centers around fundamental statistical knowledge.
- The how: Analysis techniques like customer lifetime value (CLV) evaluation, market basket analysis, customer segmentation, revenue projection, and so on.
At the intersection of these two domains, you have metrics specifically useful for e-commerce such as conversion rate, cart abandonment rate, inventory turnover, etc., and more importantly, the causal structure of those metrics e.g. in order to optimize cart abandonment rate, you need to increase the search relevance score, reduce the shipping cost, etc.
In short, to apply any large language model to a specific domain, we need to incorporate both the knowledge and the skill of that domain into the model.
In general, there are two ways to do this.
01. Fine-tune The Base Model For Domain-Specific Tasks
Fine-tuning entails taking a pre-trained model and training it on a smaller dataset that pertains specifically to your domain. This process allows the model to grasp the nuances of the domain, thereby enhancing its accuracy and performance when dealing with domain-specific tasks.
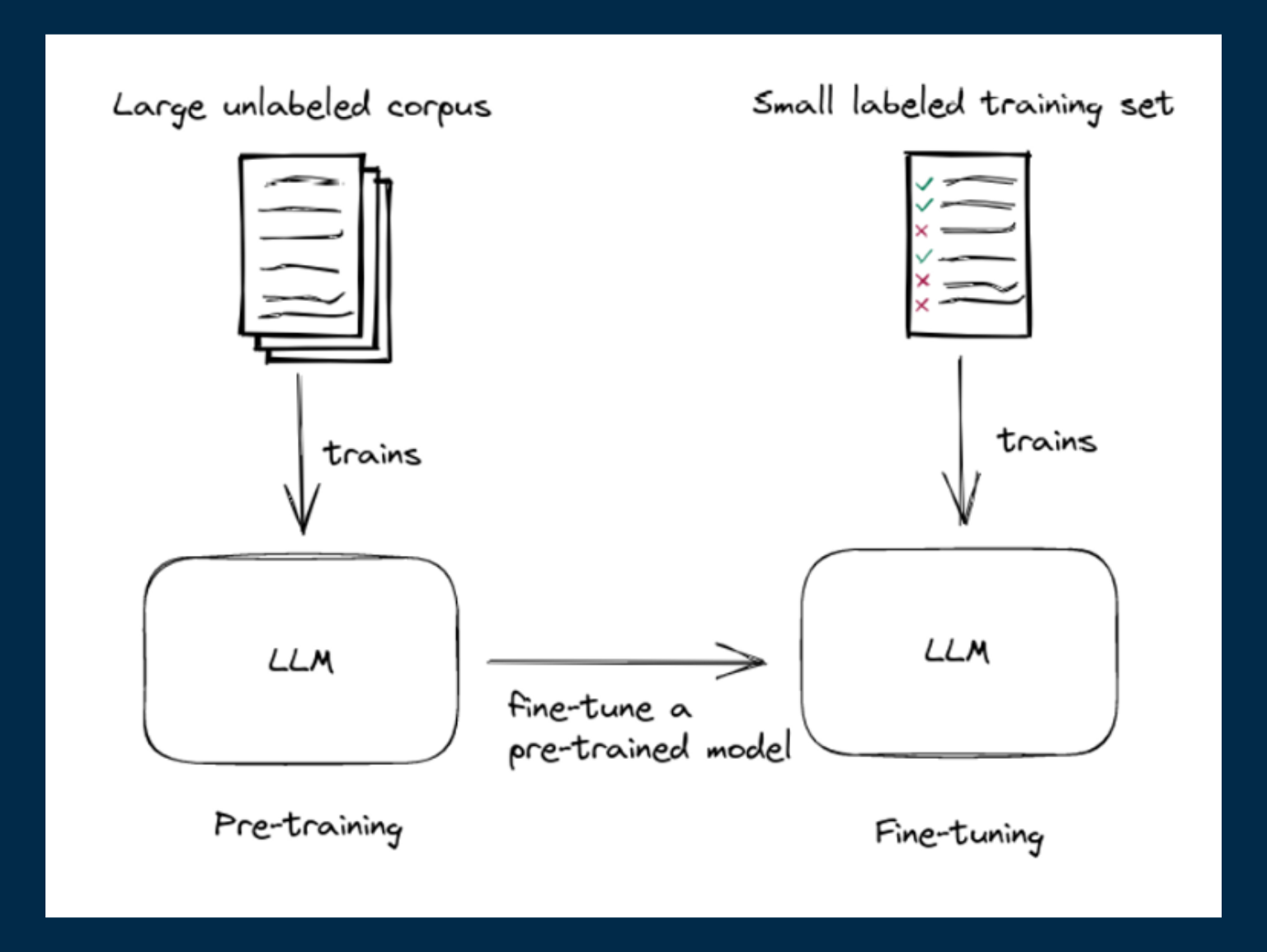
However, training a model isn't the same as storing the knowledge into a database. Think of it more like a lossy compression of the domain's knowledge, something like a "blurry JPEG of the web".
Additionally, creating a high-quality training set for a specific domain often requires substantial effort as generating it automatically usually isn't an option.
To draw an analogy, imagine hiring a data analyst intern from a liberal arts institution. They've got a fairly good grasp of the world, courtesy of their eclectic education, and hold some inklings about the ins and outs of data crunching.
With a bit of training in data analytics techniques that are relevant to your business domain, they can acquire the necessary skills to function as data analysts. However, similar to regular humans without photographic memories, they retain only the essence of the knowledge they were trained on and may occasionally rely on inaccurate information in their day-to-day work.
02. Search and Ask Method
The second way is to use the search-and-ask method, which involves combining an information retrieval component (e.g. a search engine) with the language model and incorporating the retrieved information into the LLM’s prompt input. This method allows us to provide the model with domain-specific knowledge without actually fine-tuning the model itself.
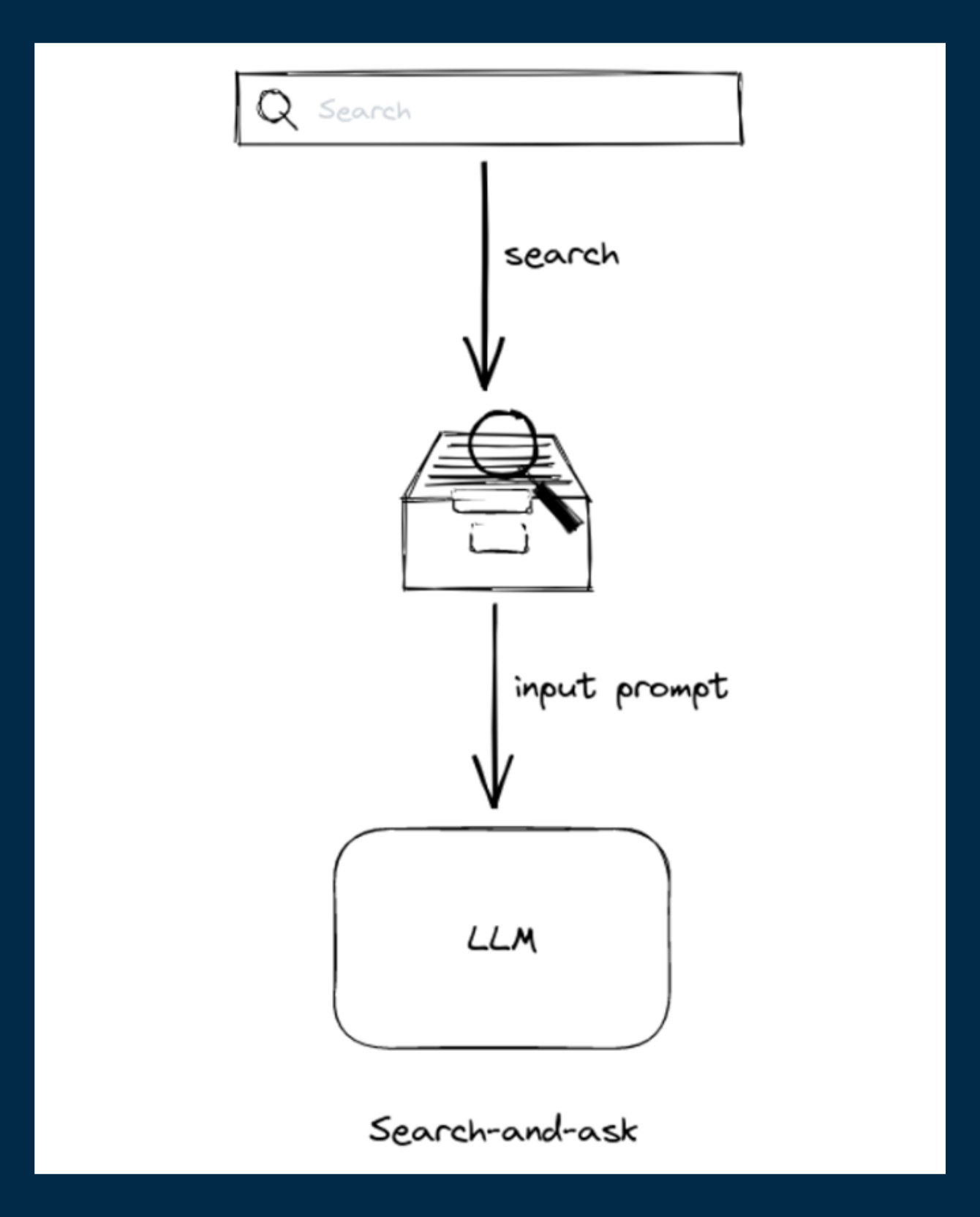
Let’s go back to our interns for a bit here. Instead of training them explicitly, we give them access to a library of business documents related to your business and data analytics techniques. Additionally, you have a librarian on standby who can retrieve the right document for our interns whenever they ask.
This approach is more accurate for raw factual retrieval of knowledge since the information is directly provided to the model. However, it suffers from the limitation of prompt input size. For example, ChatGPT's limit is 4096 tokens, while GPT-4 has a limit of 32K tokens.
Just as an intern would struggle to cram every single document onto their already cluttered workspace, LLMs can’t handle demanding queries with a high-level synthesis of large amounts of documents, or perform advanced analyses that stretch beyond their initial training. This is a huge challenge working with LLM without any known good solution.
The Cost Factor
When comparing the two approaches, there’s also the cost factor. The cost of fine-tuning is tied to the size of the model. Bigger base models mean bigger holes in your pocket. Plus, acquiring a large training dataset is both difficult and costly.
On the other hand, even though the search-and-ask approach doesn't have to share the same cost concern, it requires an external retrieval component which adds extra costs for building and maintaining that component.
Which One To Choose?
Given the 2 approaches, how can we adapt the LLM to be able to provide self-service BI to business users?
Depending on the complexity of the capabilities required, we can choose to use the search-and-ask approach for quick, simple retrieval queries such as: “Give me the list of customers in Asia Pacific region that signed up in the last 3 months”.
And for tasks with more advanced reasoning/analytics skill requirements, we can pick the fine-tuning approach: “Given the chart of conversion rate below, try to find the most important factors that affect the changes in the range”.
Most likely, both of these can be combined and used together, intelligently chosen for each of the sub-task required. Deciding when to use which is a challenging problem that will require tons of research, trial, and error to get right.
One thing is for sure, it is not quick or easy to develop a truly effective adaptation from base LLMs.
Data semantic layer and LLM
The previous section mentions 2 different approaches to adapting LLM to a data analytics domain. Both of these require a place to store the business and analytics logic to allow the LLM to train on or to get the right information on the job. This is where the data semantic layer comes in.
A quick recap: A data semantic layer is a virtual layer hovering on top of the physical data layer and serves as an intermediary between the data source and the end-user reporting or analysis tools. It is a place that let analysts define data models that map to underlying data warehouse tables, relationships between them, and especially metrics that business users are interested in.
Traditionally, most semantic layers were an intrinsic part of the BI tools. However, there has been a trend to build data semantic layer standards that are independent of the BI tools. Currently, there are ones being developed such as dbt's MetricFlow, Cube et. al.
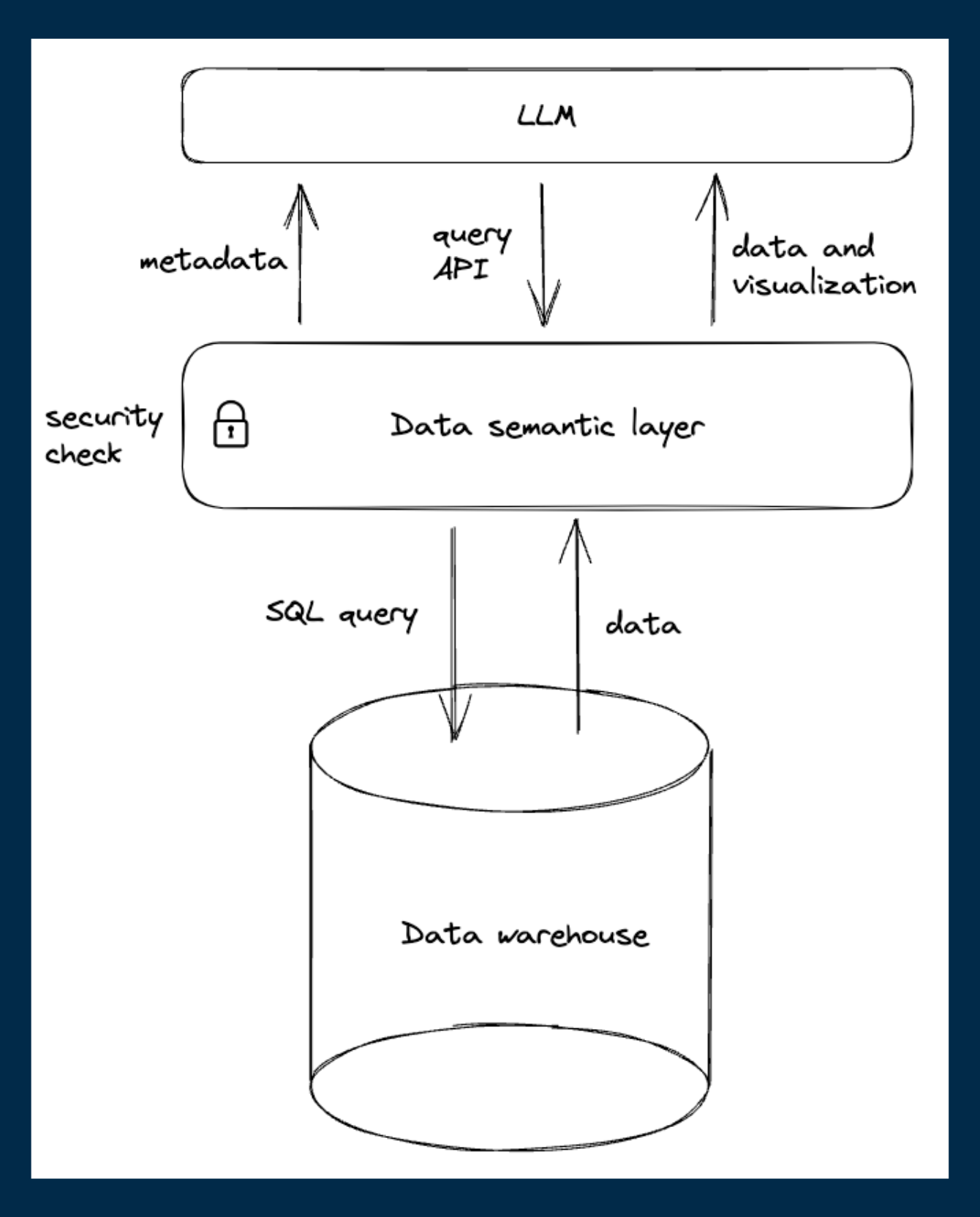
How does the LLM leverage the semantic layer?
If we recall our data analyst intern example, a semantic layer would be both the library and the librarian, assisting the interns with their tasks. Analysts can populate this “library” with analytics logic and business context, which will be supplied to the interns whenever they need it.
An important function of the semantic layer is to provide a higher level of data abstraction for the LLM to leverage. Instead of having the LLM directly generate SQL to query user data, which is brittle and error-prone - the LLM only needs to convert user requests into an API request format, or a high-level query language that the semantic layer can understand. After that, the layer will construct SQL queries using traditional, deterministic, verifiable rules that ensure the query is valid.
The layer also checks the permission rules before generating the SQL to ensure that only allowed data can be accessed by the end user. This not only improves reliability but also the security and governance of the whole system.
Conclusion and What’s Next
Hopefully, by now, you’d be convinced by what we’ve tried to prove:
- LLM indeed has true potential to drastically change the landscape of self-service analytics;
- But no, it is not a quick nor simple “plug-and-play operation” to integrate LLM technology into your BI platform;
- A semantic layer is a crucial component in any AI-assisted data analytics system.
In the next post, we’ll attempt to convince you that: Despite all the benefits of a semantic layer, the current semantic layer state-of-the-art is still not enough to build an ideal self-service experience with LLM.
Until then, let us know what you think.
What's happening in the BI world?
Join 30k+ people to get insights from BI practitioners around the globe. In your inbox. Every week. Learn more
No spam, ever. We respect your email privacy. Unsubscribe anytime.
