
Three Data Industry Questions We're Investigating For The New Year

In 2020, we started off the year with a deep dive into the rise and fall of OLAP cubes. In 2021, we’re starting off the year with a bunch of deep dives into various data industry topics — investigations that will be spread over the next couple of months.
We think these topics might best be represented by a series of questions. The questions are usually about the meta of data analytics — that is, about changing technology needs, industry shifts, or emerging data roles. We think these questions are interesting to the data practitioner today; if nothing else, they represent areas of change that may be consequential for the next couple of years.
Here are three questions we’re asking this year.
Are Data Lakes Really Necessary?
In The Data Warehouse Toolkit, Ralph Kimball and Margy Ross described the quintessential data stack of the 80s and 90s. They called it the ‘data warehouse bus architecture’ and illustrated it like so:
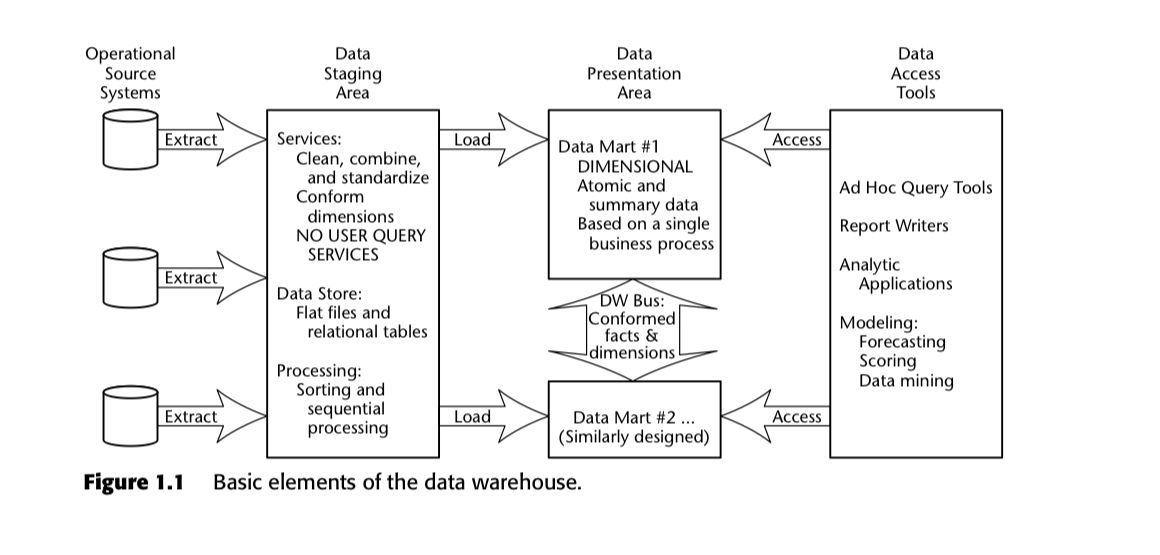
Notice how every data source feeds into a ‘staging area’, separate from what they described as the ‘data presentation area’. As we’ve covered elsewhere, this approach was partially influenced by the technological limitations of the time — the relational databases and OLAP cubes of Kimball’s era weren’t particularly powerful, and therefore demanded multiple processing steps.
Of course, the rise of massively parallel processing (MPP) data warehouses have changed that quite a bit. But perhaps we still hold on too tightly to the idea of keeping a ‘staging area’ in our data architectures. In 2010, Pentaho CTO James Dixon coined the term ‘data lake’, essentially updating the idea of a staging area for the big data era.
We’ve always been rather agnostic about data lakes. In The Analytics Setup Guidebook, for instance, we wrote:
We have no strong feelings about data lakes. The point of ELT is to load the unstructured data into your data warehouse first, and then transform within, rather than transforming data in-flight through a pipelining tool. Whether this raw data sits in an object bucket before loading is of little concern to us.
But perhaps it’s time to update our beliefs. Over the last couple of months, we’ve been hearing from a number of veteran business intelligence practitioners that a data lake isn’t really needed for modern data analytics. In fact, some of them go so far as to say that a lake is just a maintenance nightmare that’s waiting to happen. This stance isn’t reflected in all of our customer engagements — in fact, many of the data teams that we serve assume that a lake is a standard part of the data stack.
How mainstream is this view? If a lake is necessary for some data teams, but not for others, what differentiates their use cases? This seems like an important empirical question to dig into.
Data Infrastructure for both AI and Analytics?
One answer to the data lake question might be that teams who do machine learning still require the use of a data lake. This seems to be the case if we look at the Andreesen Horowitz Emerging Architectures for Modern Data Infrastructure report, released in October last year. The report asserted that complex data science and ML workloads nearly always feature a lake at the center of the entire stack.
A month later, the firm released a podcast episode titled ‘The Great Data Debate’. One of the topics of that debate was the necessity of data lakes in AI-oriented data infrastructures, compared to, say, having that data live in data warehouses — which already sit at the heart of a modern analytics stack. Bob Muglia, the former CEO of Snowflake, was quick to assert that everything would eventually fold into cloud data warehouses; the other panelists disagreed.
Our take is that it’s too early to tell what the ideal ‘hybrid’ data infrastructure should look like — that is, one that can handle both AI and analytics. We know that there is an emerging class of tools that have started to attack this pain point. We know that these tool companies are more often than not venture-backed, which means a clash of approaches is inevitable — both from the vendors and from the VC firms that back them. (Expect to see more such ‘reports’ and ‘debates’ in the near future!)
We also know that we have to keep an eye on the development of this topic, given our position in the industry: if a particular infrastructure looks like it’s going to win, then we’re going to have to evolve our product to take that into account.
What’s the Current State of Analytics Engineering?
In January of 2019, Michael Kaminsky wrote a post over at Locally Optimistic titled The Analytics Engineer, arguing that there should be a new title for an emerging role in the data team. A few months later, the folks at dbt wrote When did analytics engineering become a thing? And why? and then proceeded to change their entire company positioning to that of servicing the analytics engineer. (At the time of this post, the dbt home page reads “Your entire analytics engineering workflow”).
We think that analytics engineering as a concept makes perfect sense — in fact, a few weeks before Kaminsky published his post, our co-founder, Huy, was saying that the analysts who work with our tool don’t do the same things that analysts working with Tableau or PowerBI do in their day-to-day jobs. This was both weird and a little worrying (a data analyst we knew said he was afraid he would become unemployable!) But then it became clear that other people in the industry saw the same changes, and we collectively breathed a sigh of relief.
But what is the current state of analytics engineering? What are the job expectations? What does the career path look like? How do you hire for it? What is the job, exactly?
The best post I’ve seen on the topic is this summary by Anna Hiem over at Data Council, but even then it is rather light on details. I suspect that it’s still too early to know what the analytics engineering role is — the same way that people used to call data scientists ‘overhyped statisticians’ when the title first gained traction.
So: what do we currently know about analytics engineering as a discipline? Who practices it? Hell, what are the best practices?
We should find out.